Django ORM – 多表实例(聚合与分组查询)
聚合查询(aggregate)
聚合查询函数是对一组值执行计算,并返回单个值。
Django 使用聚合查询前要先从 django.db.models 引入 Avg、Max、Min、Count、Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
聚合查询返回值的数据类型是字典。
聚合函数 aggregate() 是 QuerySet 的一个终止子句, 生成的一个汇总值,相当于 count()。
使用 aggregate() 后,数据类型就变为字典,不能再使用 QuerySet 数据类型的一些 API 了。
日期数据类型(DateField)可以用 Max 和 Min。
返回的字典中:键的名称默认是(属性名称加上__聚合函数名),值是计算出来的聚合值。
如果要自定义返回字典的键的名称,可以起别名:
aggregate(别名 = 聚合函数名("属性名称"))
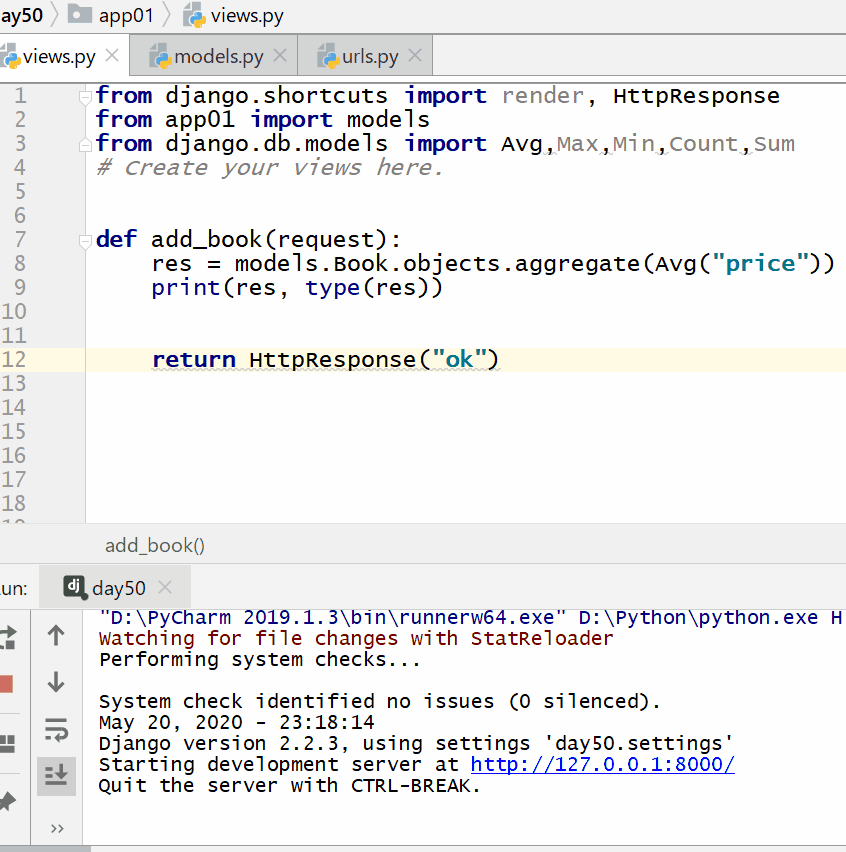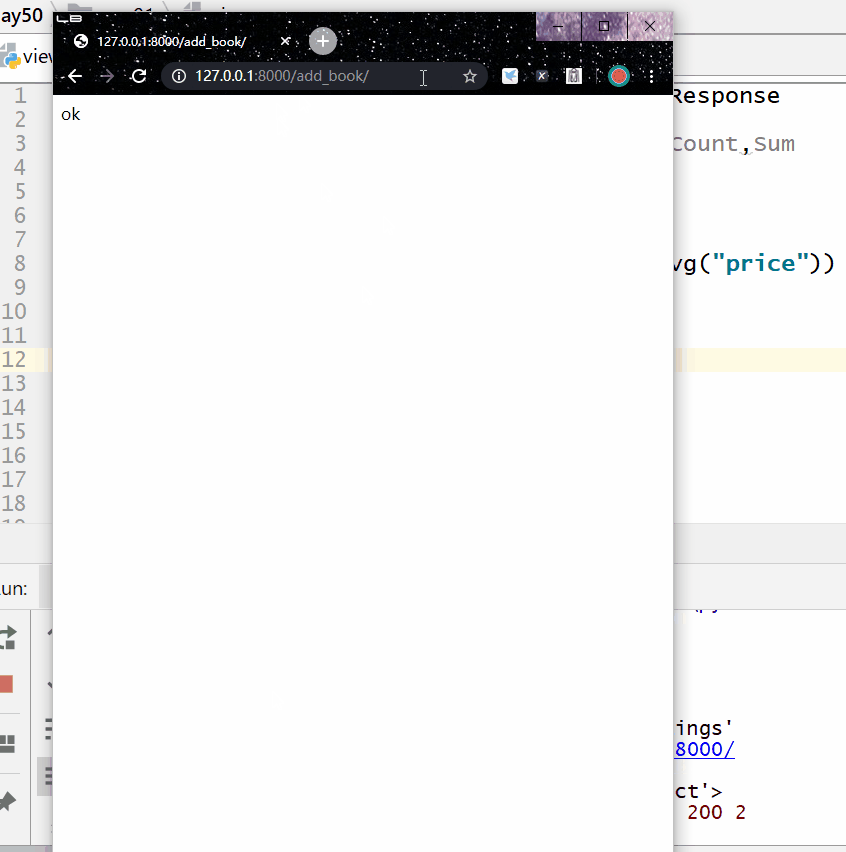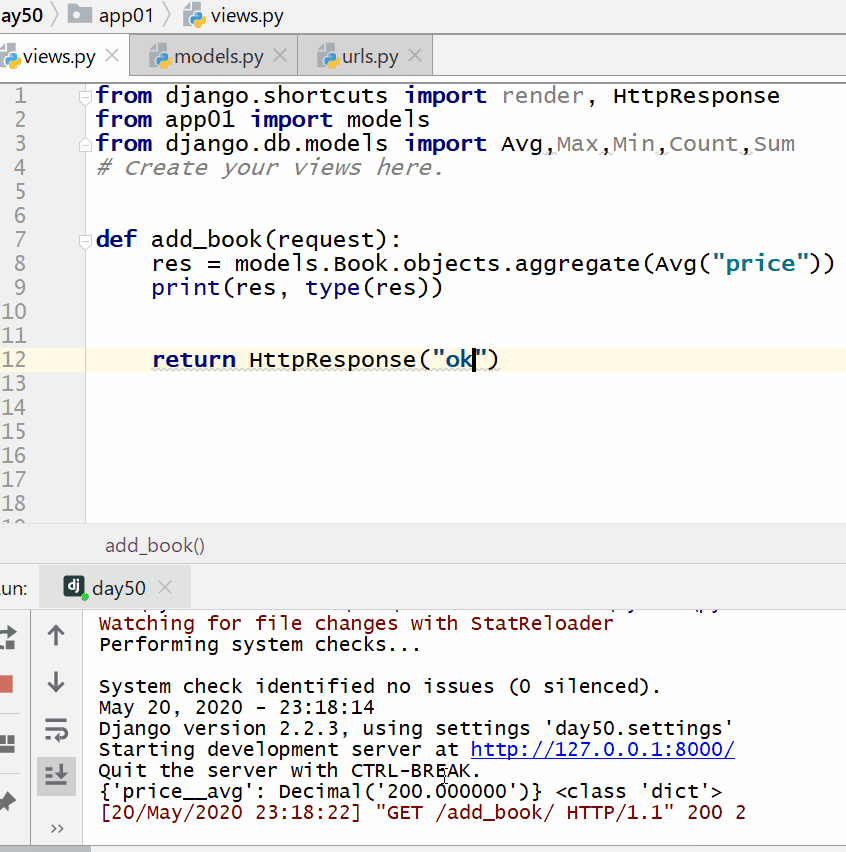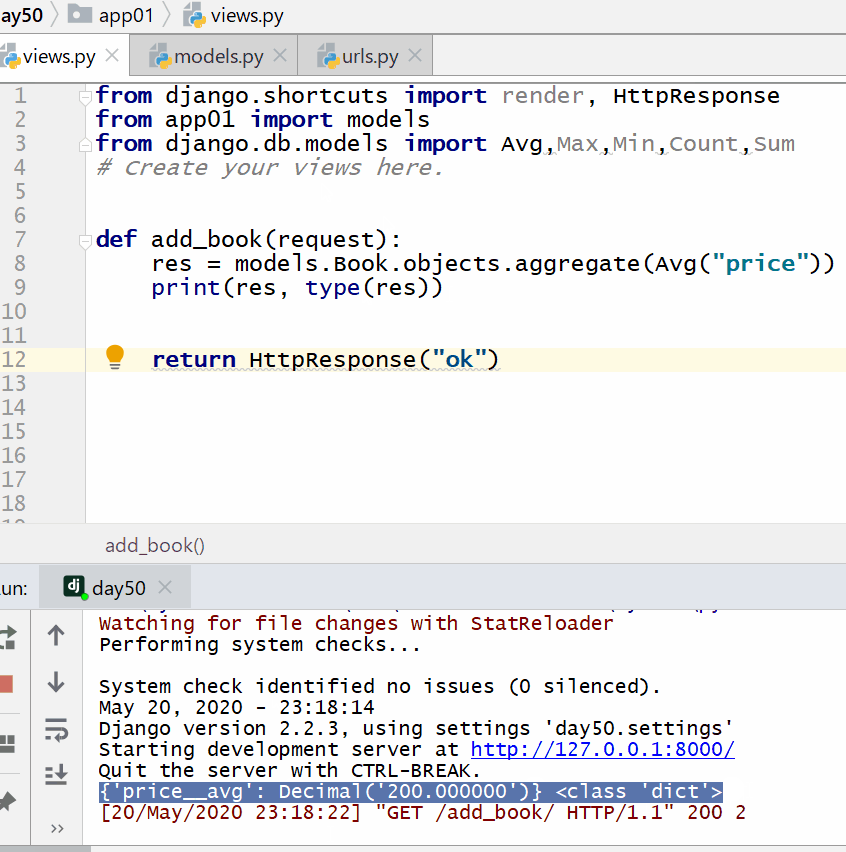
计算所有图书的平均价格:
实例
...
res = models. Book . objects . aggregate ( Avg ( "price" ) )
print ( res , type ( res ) )
...
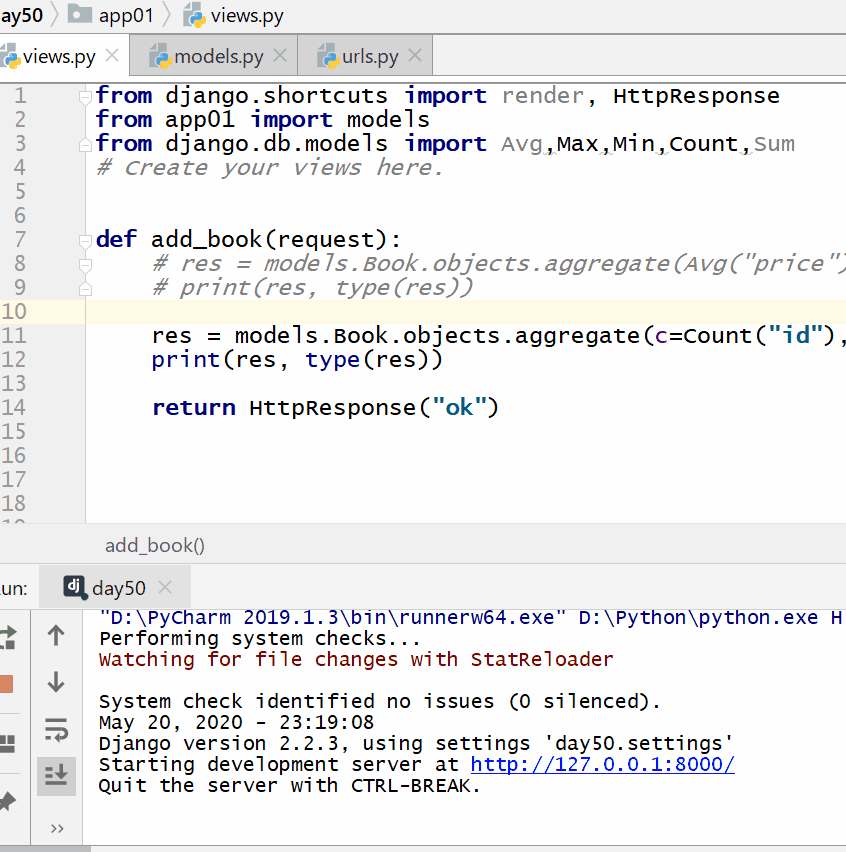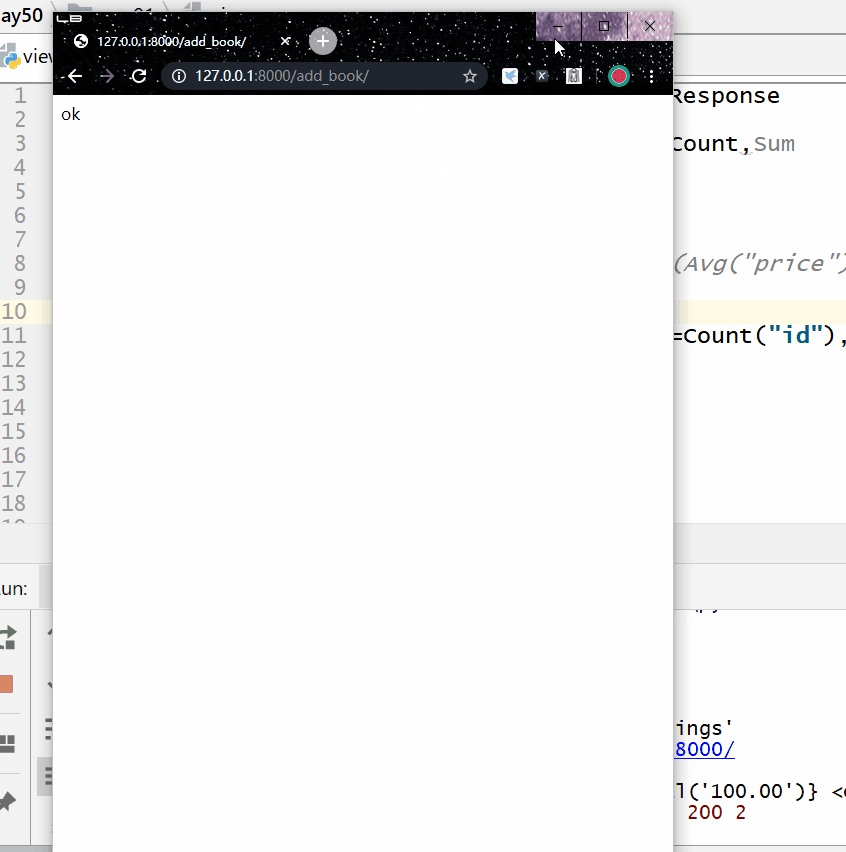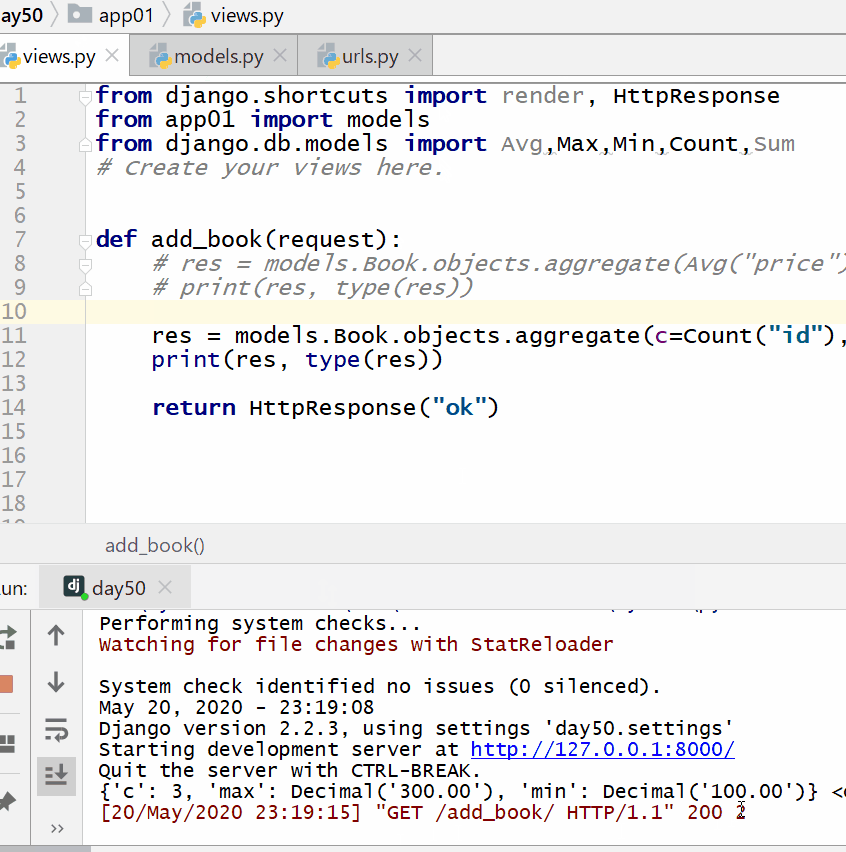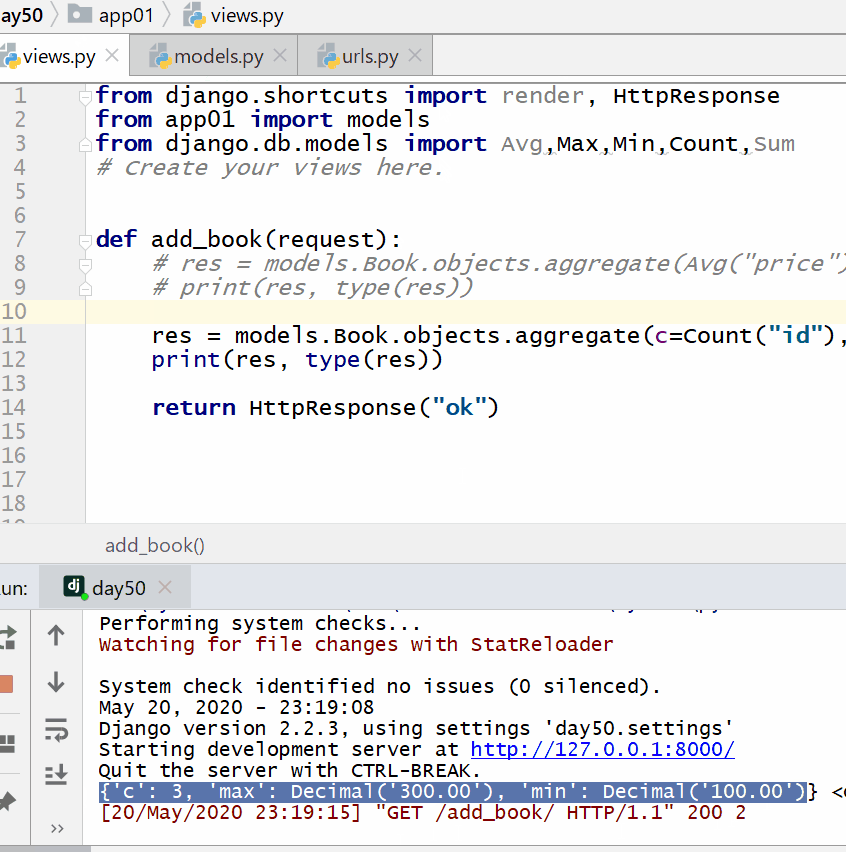
计算所有图书的数量、最贵价格和最便宜价格:
实例
print ( res , type ( res )
分组查询(annotate)
分组查询一般会用到聚合函数,所以使用前要先从 django.db.models 引入 Avg,Max,Min,Count,Sum(首字母大写)。
from django.db.models import Avg,Max,Min,Count,Sum # 引入函数
返回值:
- 分组后,用 values 取值,则返回值是 QuerySet 数据类型里面为一个个字典;
- 分组后,用 values_list 取值,则返回值是 QuerySet 数据类型里面为一个个元组。
MySQL 中的 limit 相当于 ORM 中的 QuerySet 数据类型的切片。
注意:
annotate 里面放聚合函数。
-
values 或者 values_list 放在 annotate 前面: values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
-
values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
准备数据和创建模型
models.py
name = models. CharField ( max_length = 32 )
age = models. IntegerField ( )
salary = models. DecimalField ( max_digits = 8 , decimal_places = 2 )
dep = models. CharField ( max_length = 32 )
province = models. CharField ( max_length = 32 )
class Emps ( models. Model ) :
name = models. CharField ( max_length = 32 )
age = models. IntegerField ( )
salary = models. DecimalField ( max_digits = 8 , decimal_places = 2 )
dep = models. ForeignKey ( "Dep" , on_delete = models. CASCADE )
province = models. CharField ( max_length = 32 )
class Dep ( models. Model ) :
title = models. CharField ( max_length = 32 )
数据:
在 MySQL 命令行中执行:
统计每一个出版社的最便宜的书的价格:
实例
print ( res )
命令行中可以看到以下输出:
<QuerySet [{'name': '云搜索出版社', 'in_price': Decimal('100.00')}, {'name': '明教出版社', 'in_price': Decimal('300.00')}]>

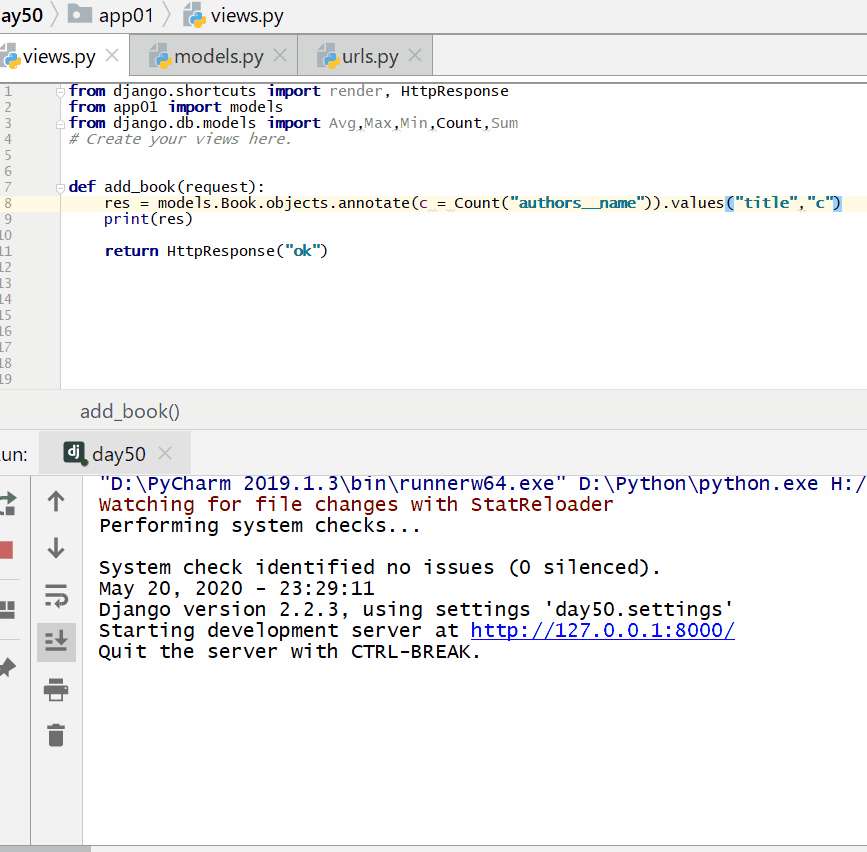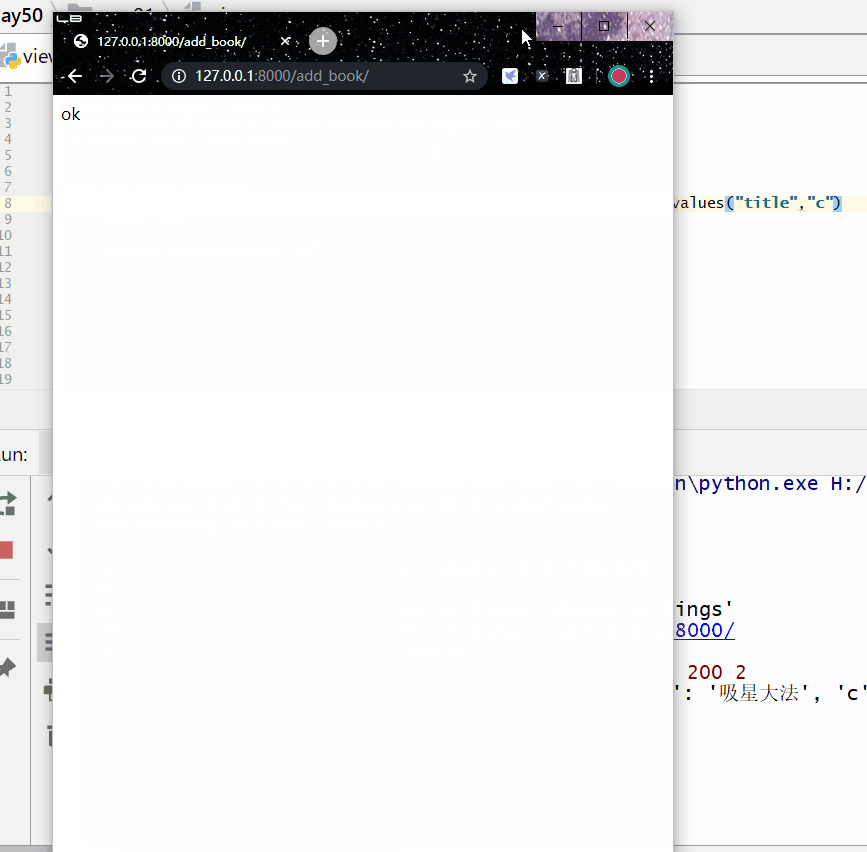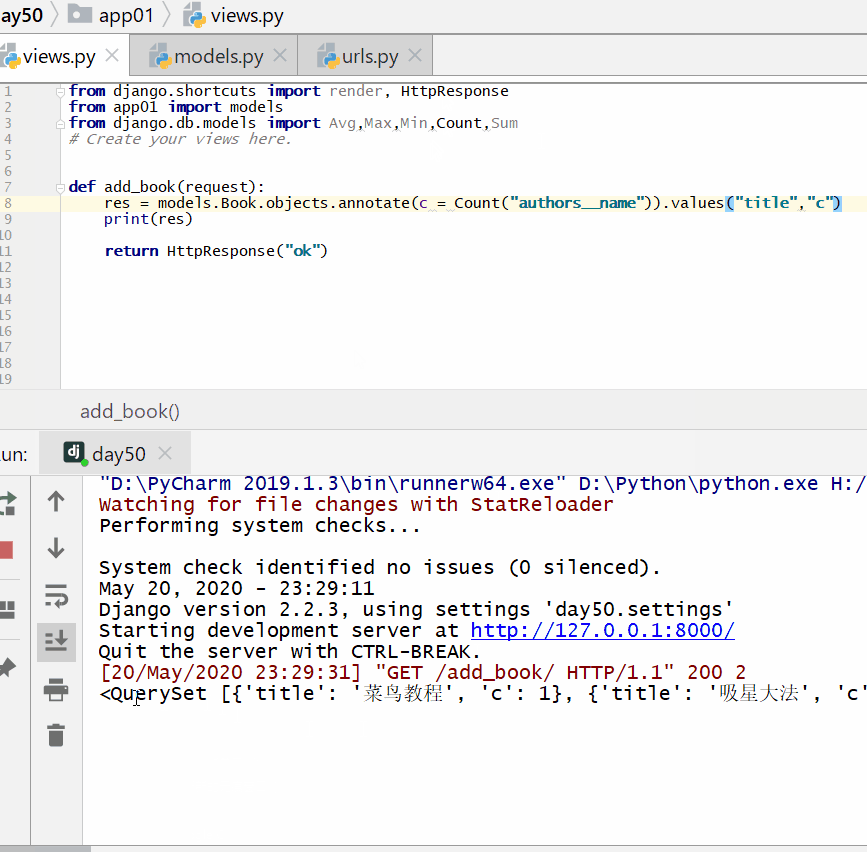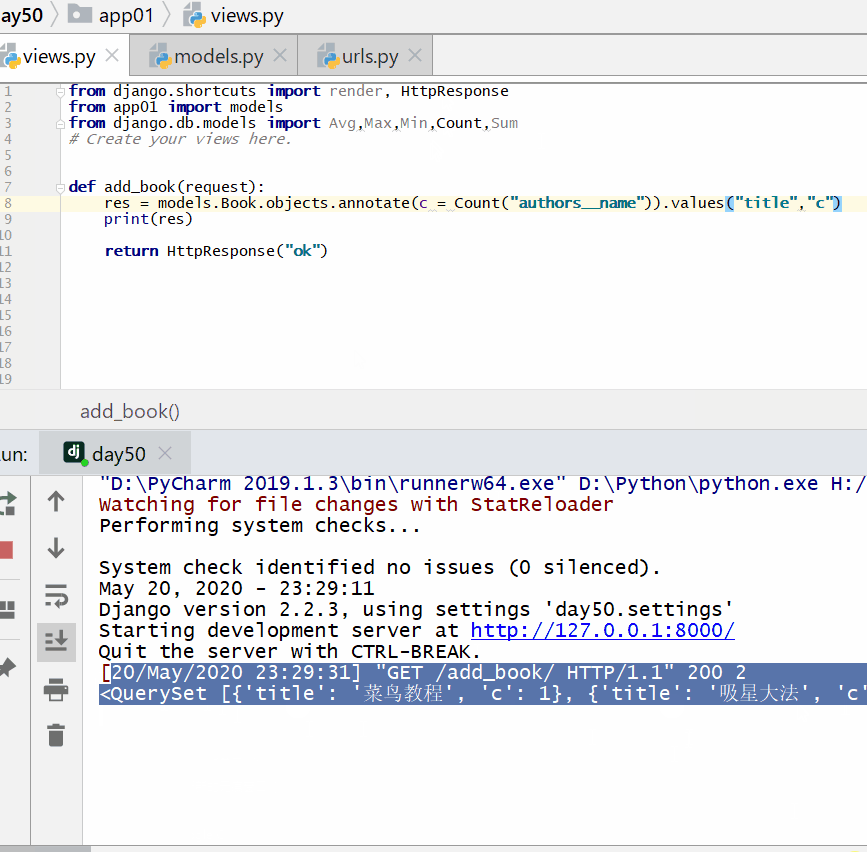
统计每一本书的作者个数:
实例
print ( res )
<QuerySet [{'title': '云搜索MX教程', 'c': 1}, {'title': '吸星大法', 'c': 1}, {'title': '冲灵剑法', 'c': 1}]>
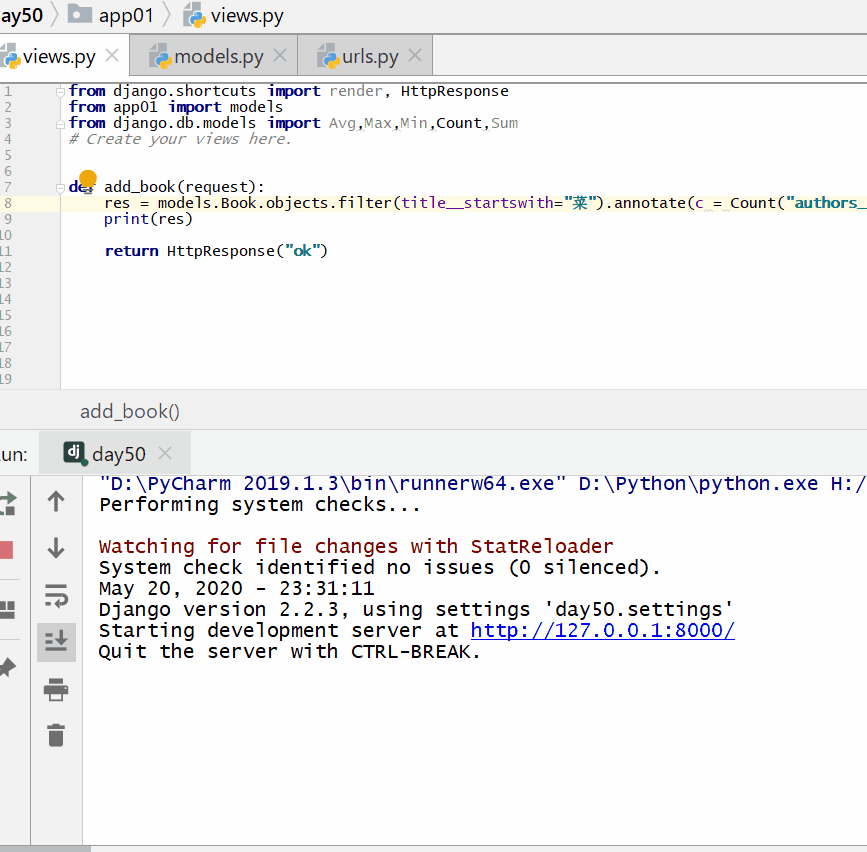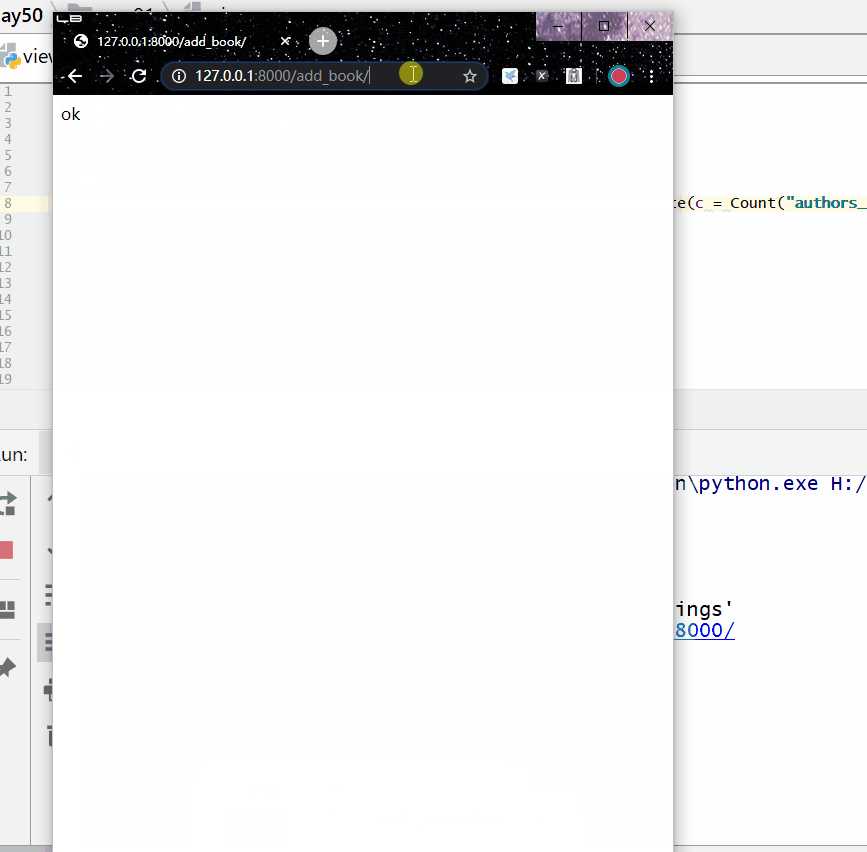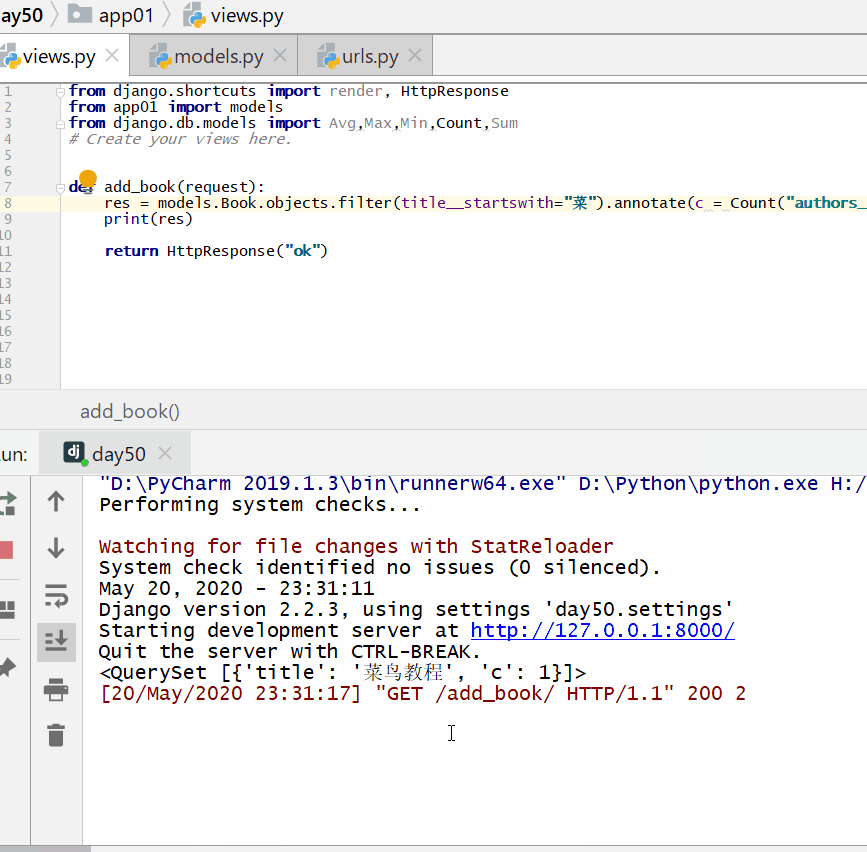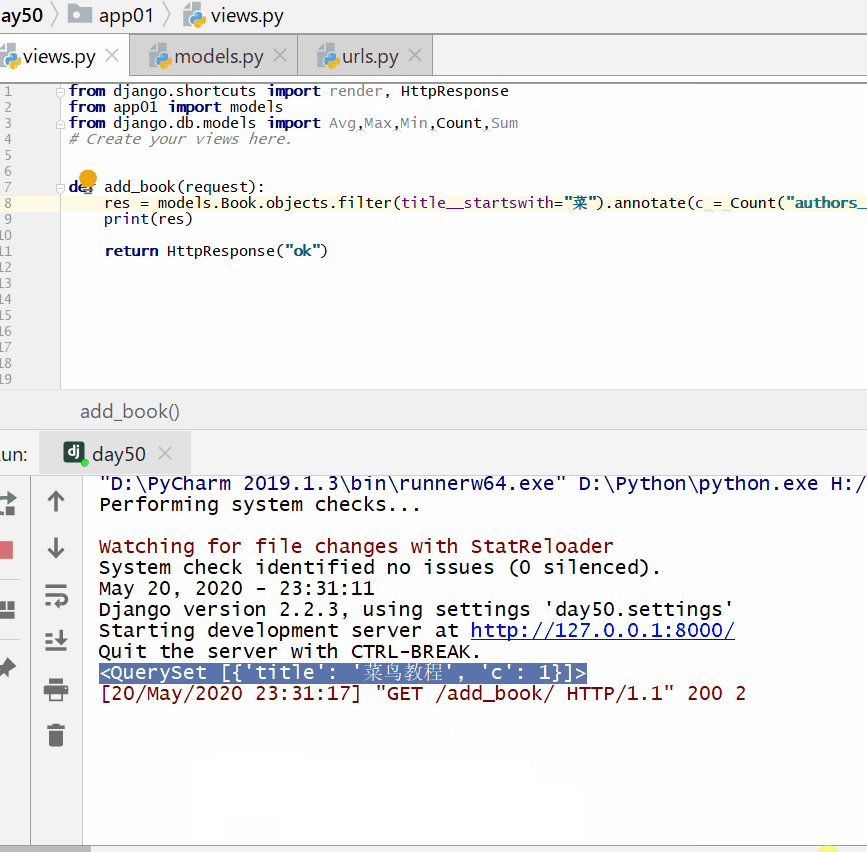
统计每一本以"菜"开头的书籍的作者个数:
实例
print ( res )
统计不止一个作者的图书名称:
实例
print ( res )
<QuerySet [{'title': '云搜索MX教程', 'c': 1}, {'title': '吸星大法', 'c': 1}, {'title': '冲灵剑法', 'c': 1}]>
根据一本图书作者数量的多少对查询集 QuerySet 进行降序排序:
实例
print ( res )
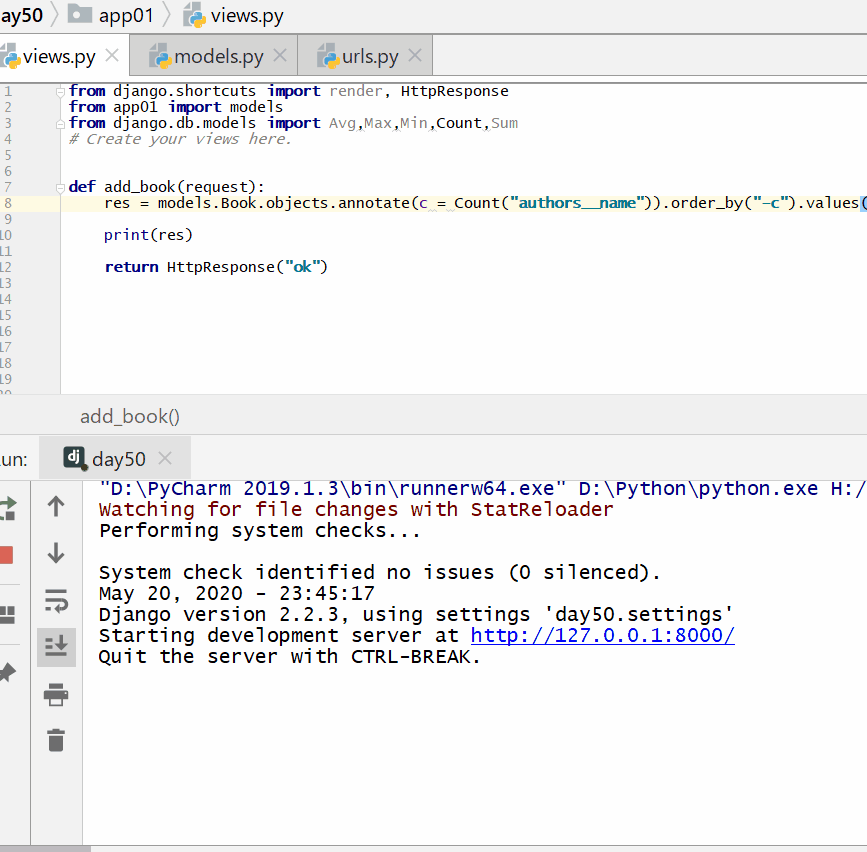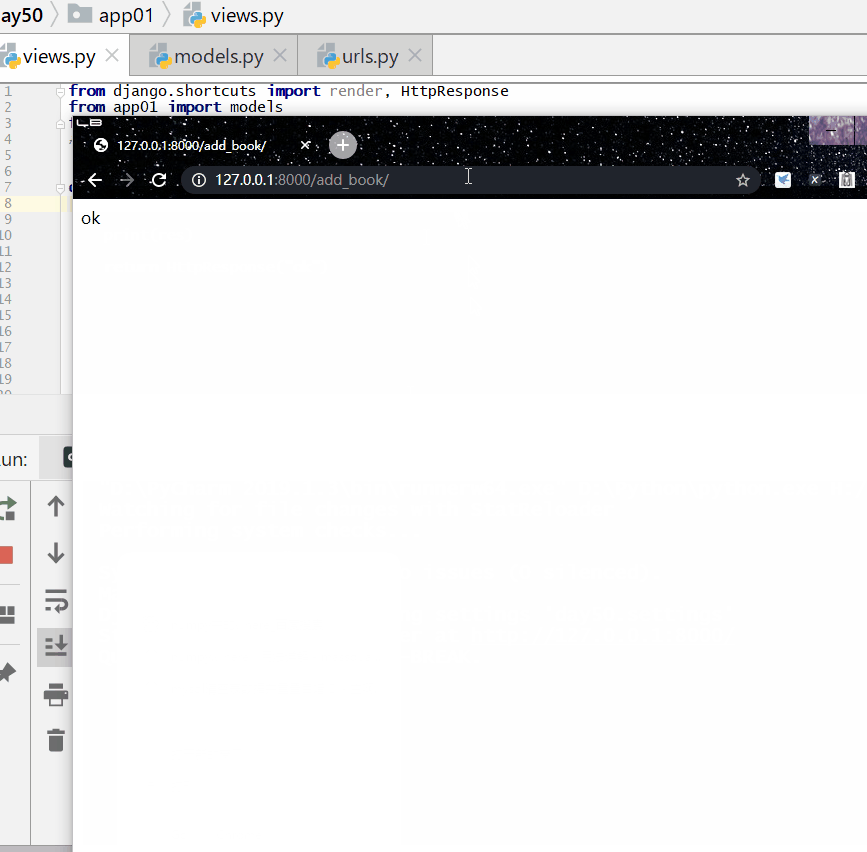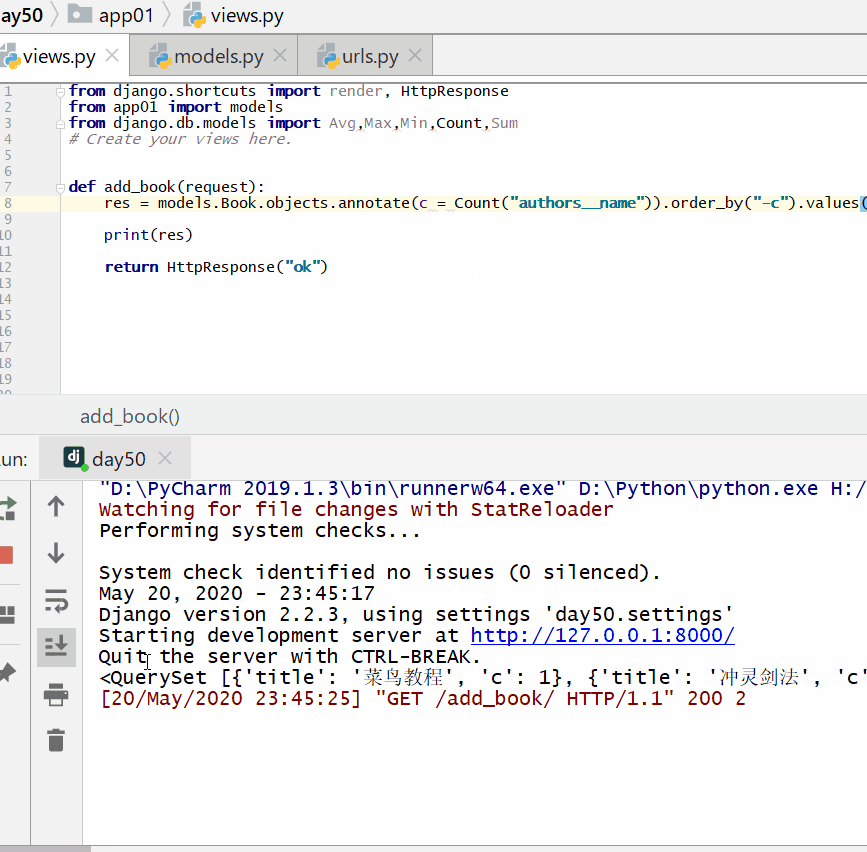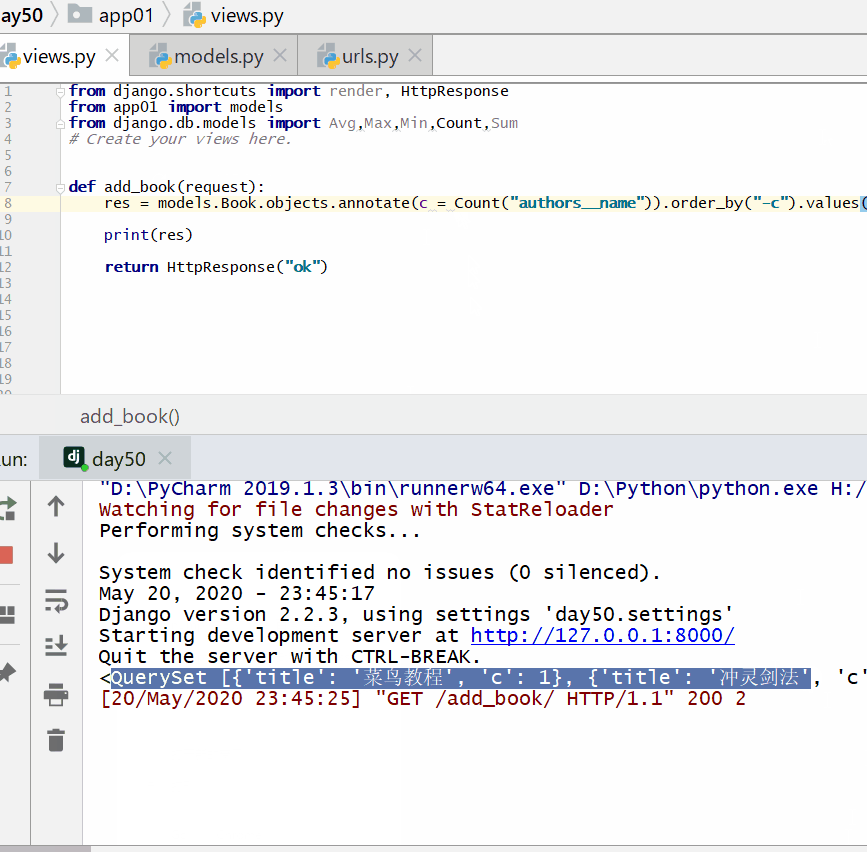
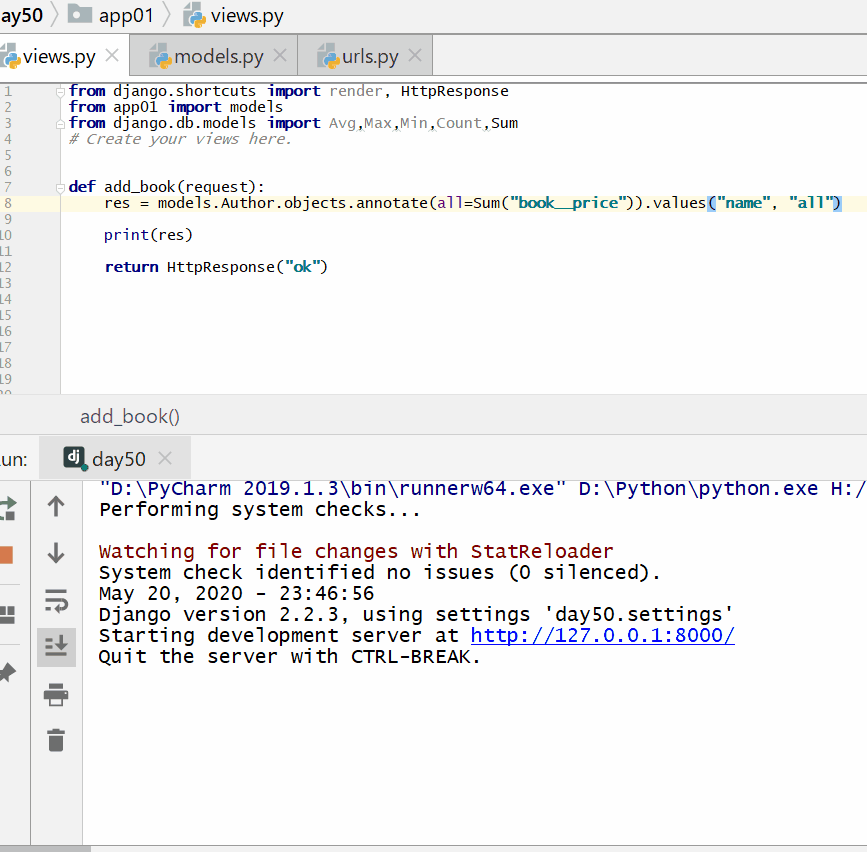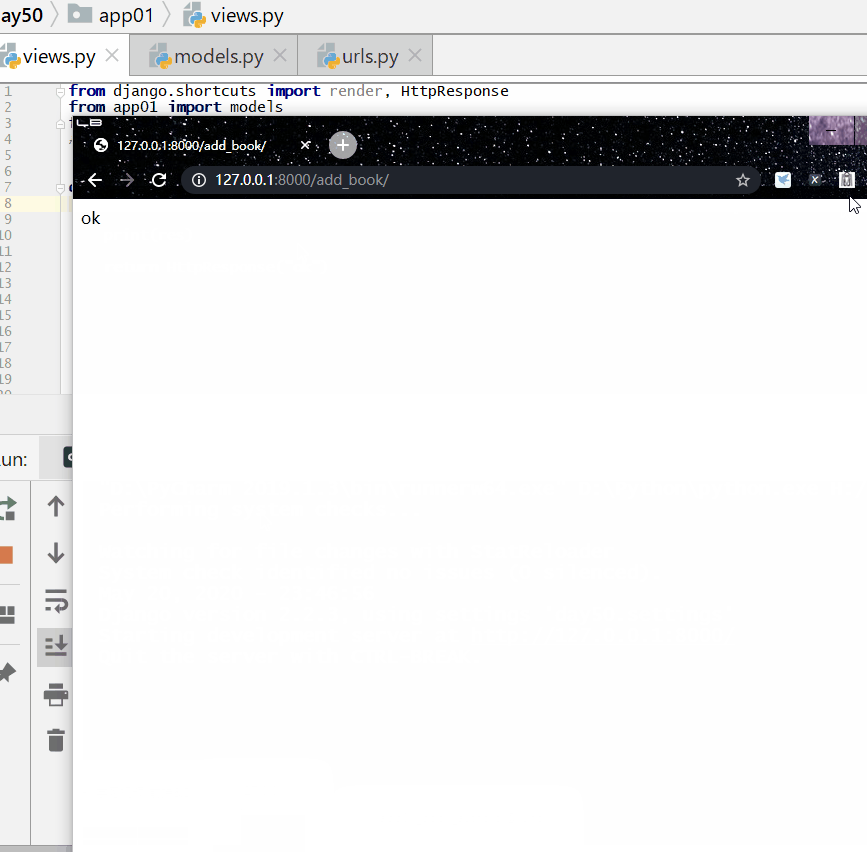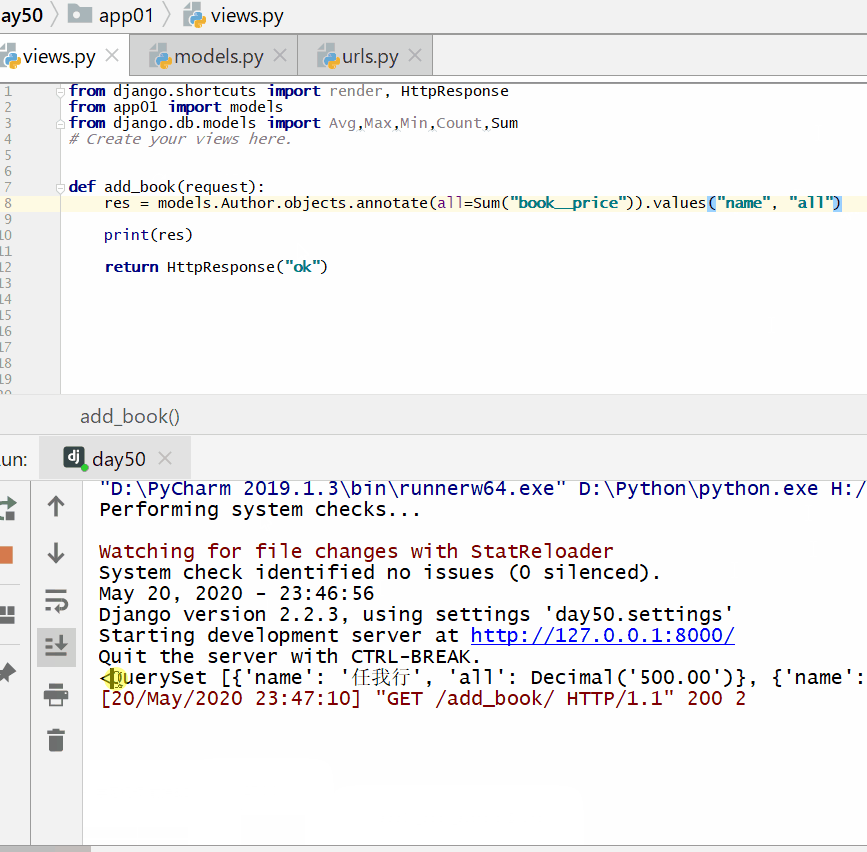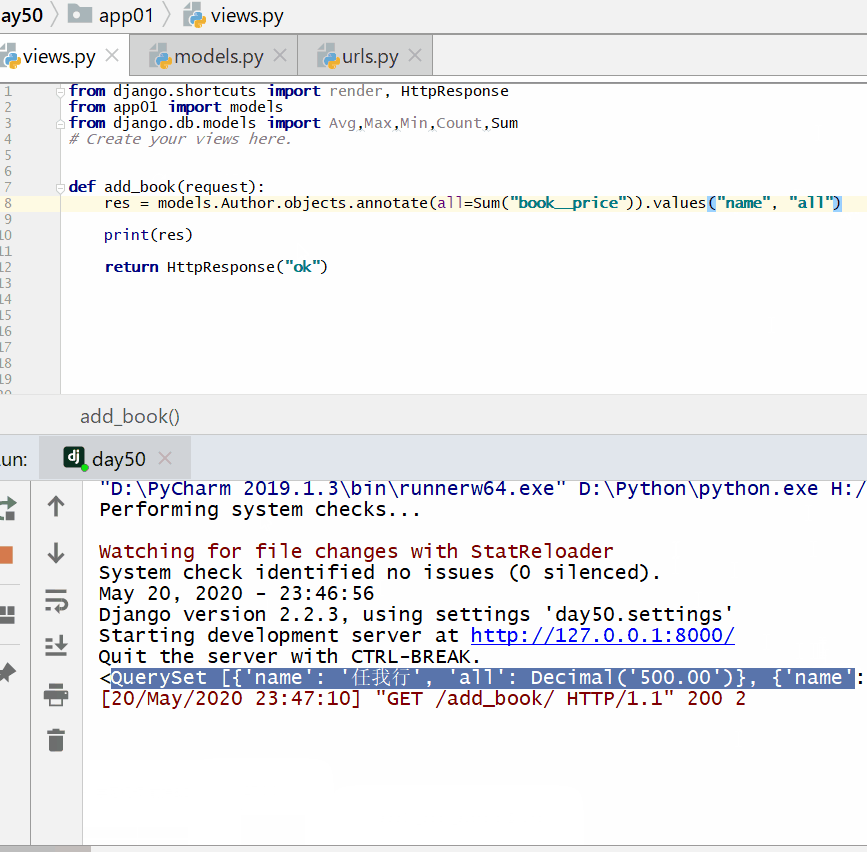
查询各个作者出的书的总价格:
实例
print ( res )
F() 查询
F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
之前构造的过滤器都只是将字段值与某个常量做比较,如果想要对两个字段的值做比较,就需要用到 F()。
使用前要先从 django.db.models 引入 F:
from django.db.models import F
用法:
F("字段名称")
F 动态获取对象字段的值,可以进行运算。
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取余的操作。
修改操作(update)也可以使用 F() 函数。
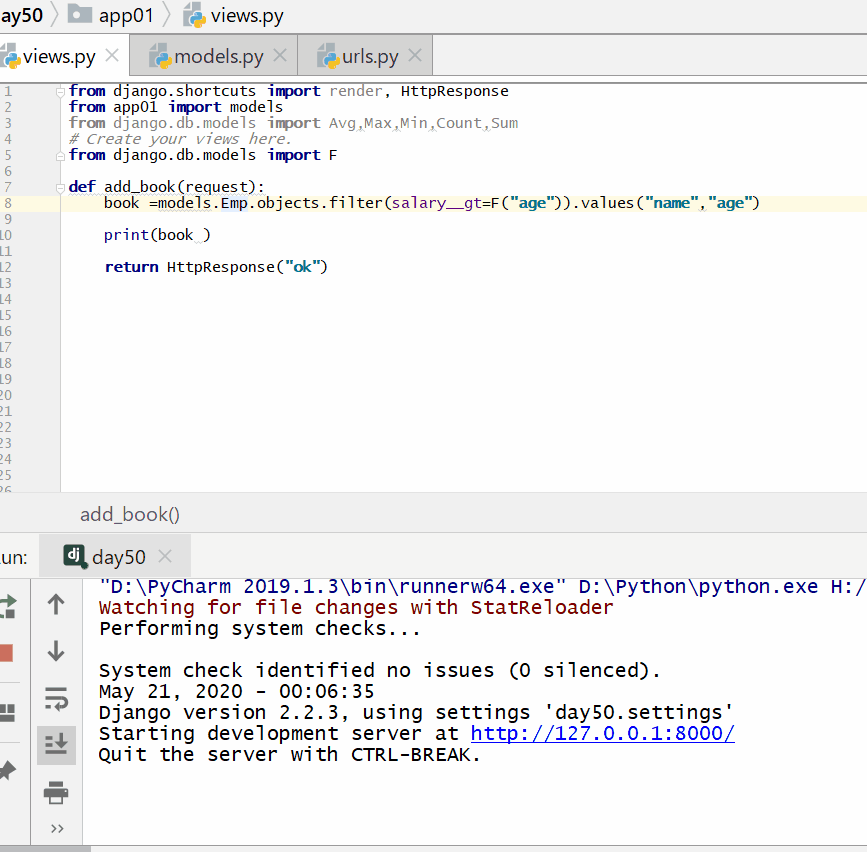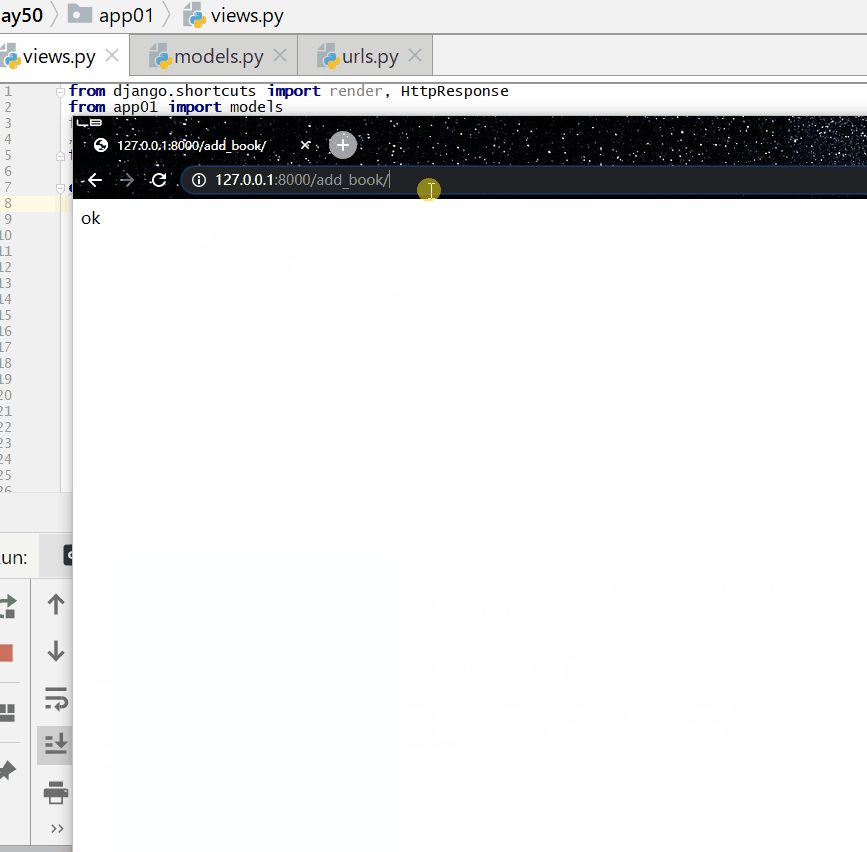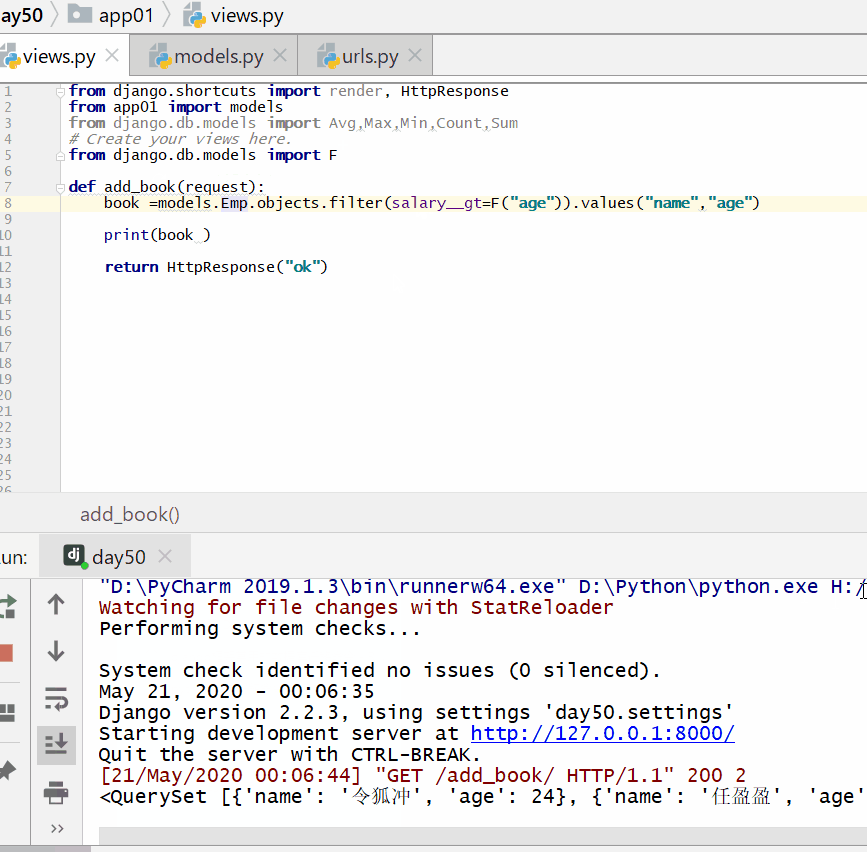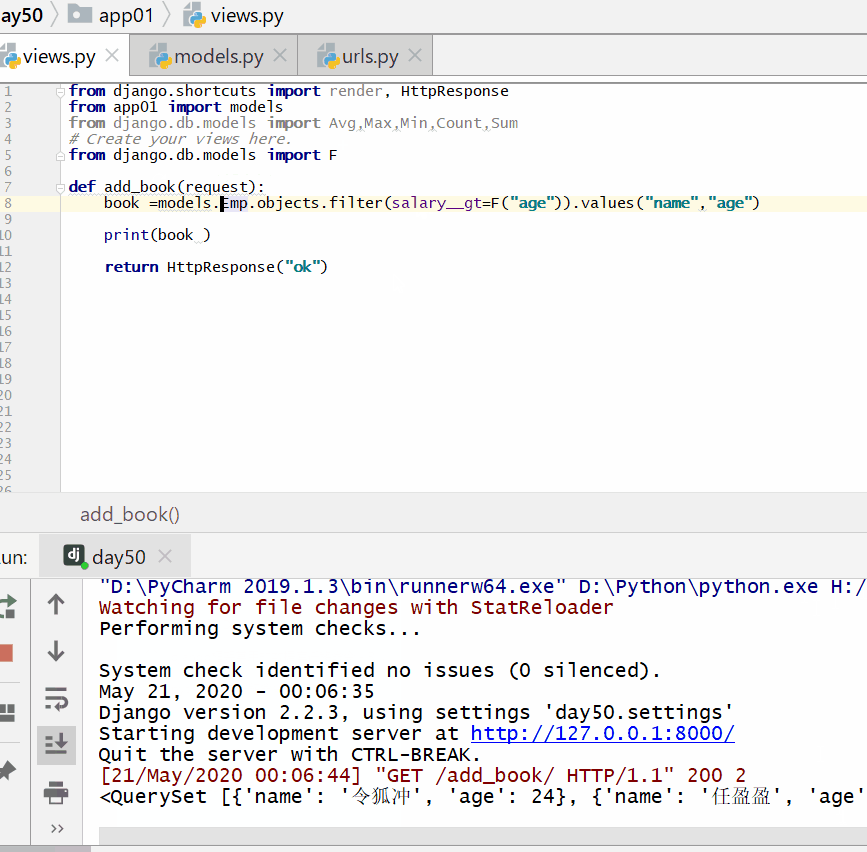
查询工资大于年龄的人:
实例
...
book = models. Emp . objects . filter ( salary__gt = F ( "age" ) ) . values ( "name" , "age" )
...
将每一本书的价格提高100元:
实例
print ( res )

Q() 查询
使用前要先从 django.db.models 引入 Q:from django.db.models import Q
用法:
Q(条件判断)
例如:
Q(title__startswith="菜")
之前构造的过滤器里的多个条件的关系都是 and,如果需要执行更复杂的查询(例如 or 语句),就可以使用 Q 。
Q 对象可以使用 &_ ~ (与 或 非)操作符进行组合。
优先级从高到低:~ & |。
可以混合使用 Q 对象和关键字参数,Q 对象和关键字参数是用"and"拼在一起的(即将逗号看成 and ),但是 Q 对象必须位于所有关键字参数的前面。
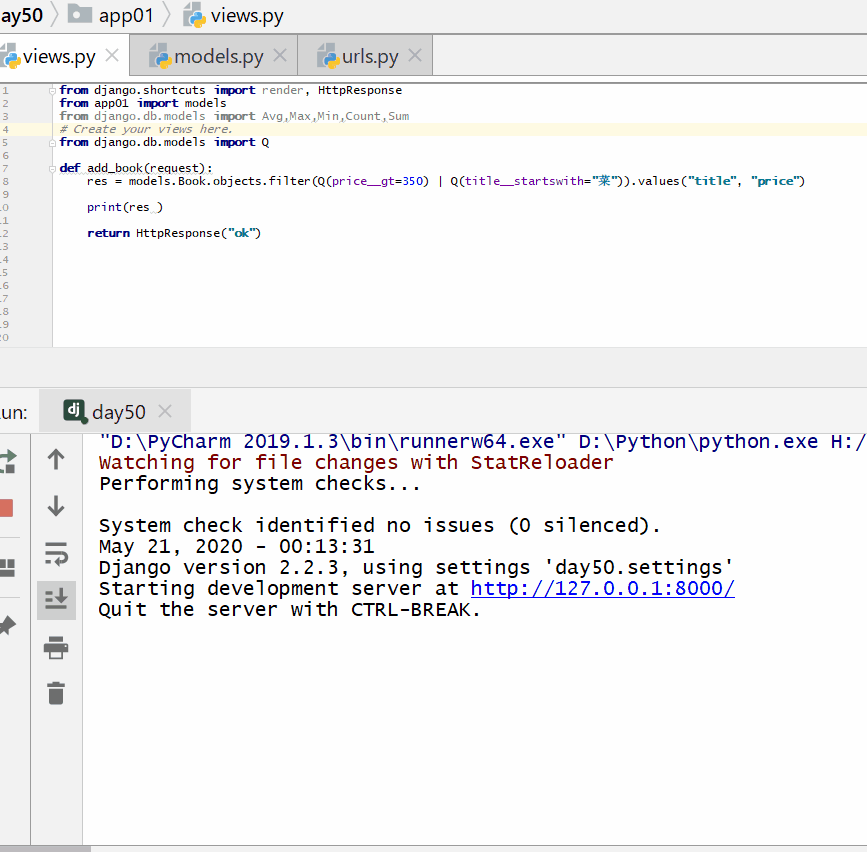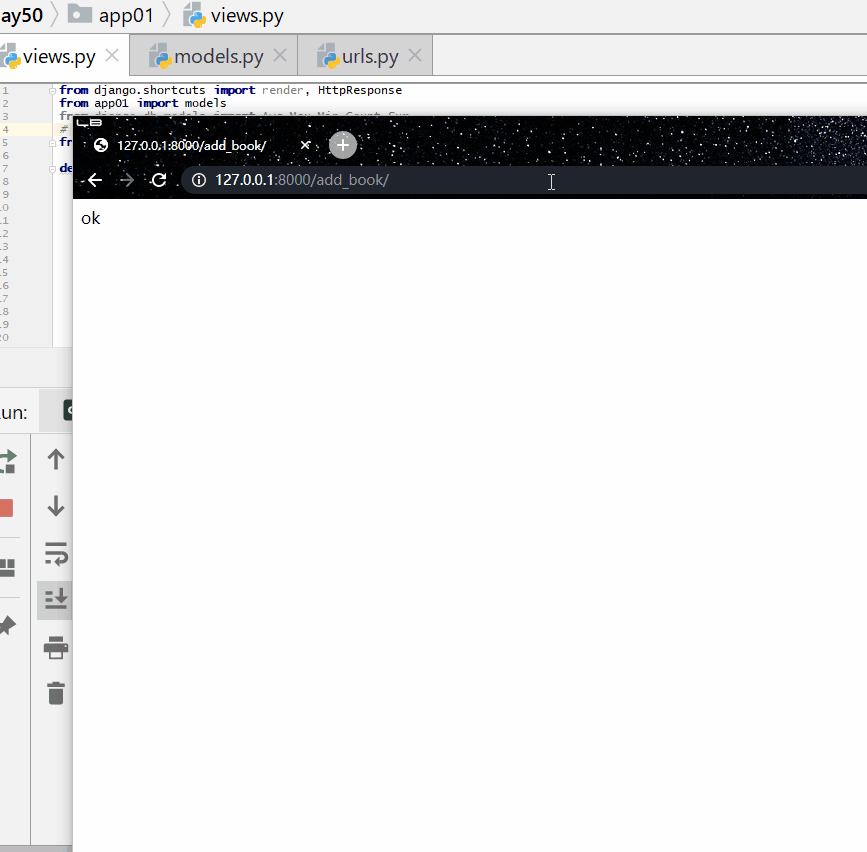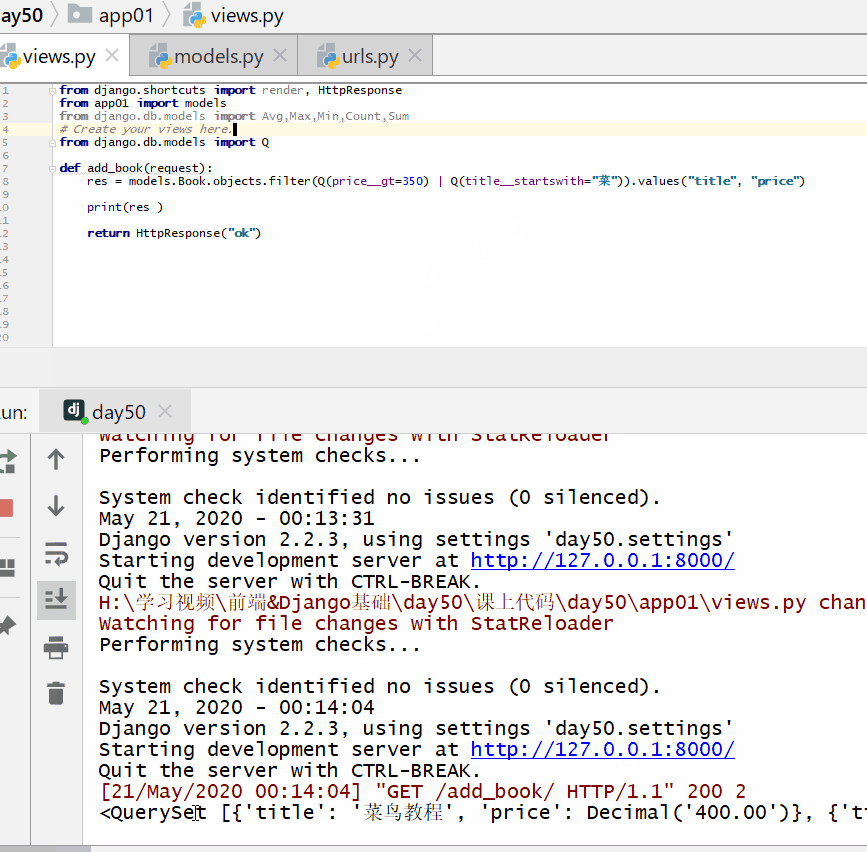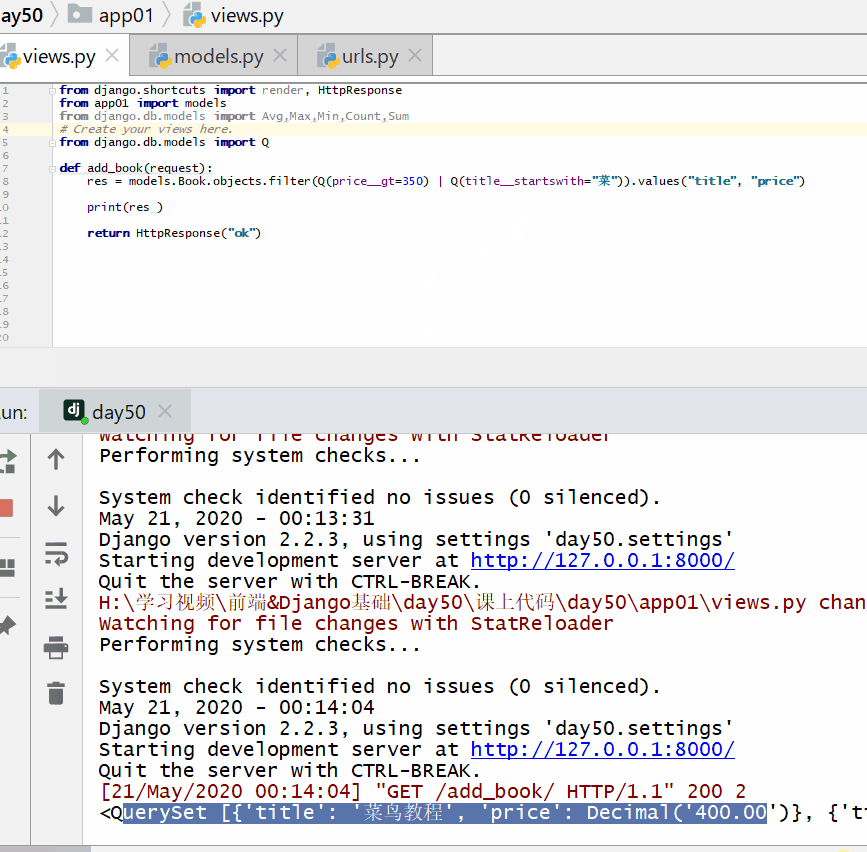
查询价格大于 350 或者名称以菜开头的书籍的名称和价格。
from django.db.models import Q实例
res = models. Book . objects . filter ( Q ( price__gt = 350 ) |Q ( title__startswith = "菜" ) ) . values ( "title" , "price" )
print ( res )
...
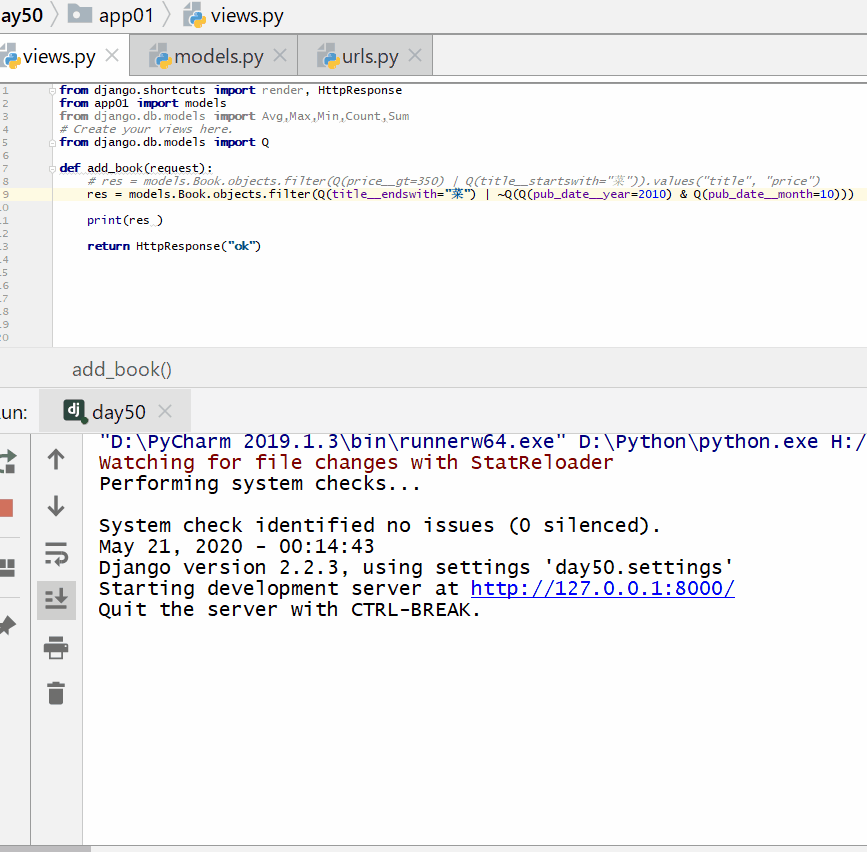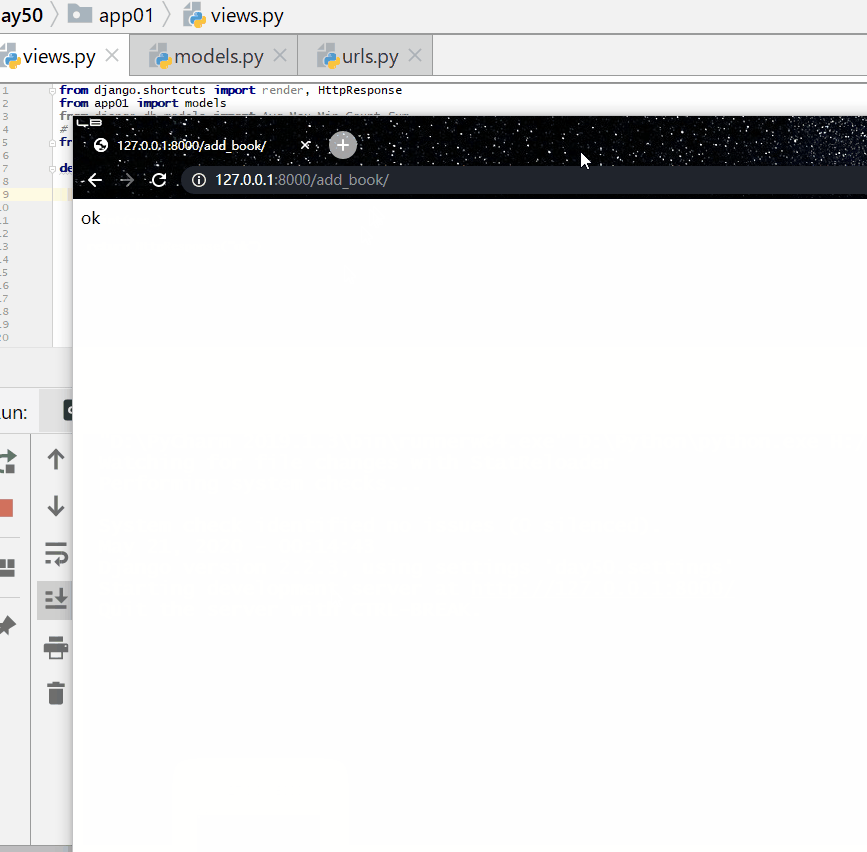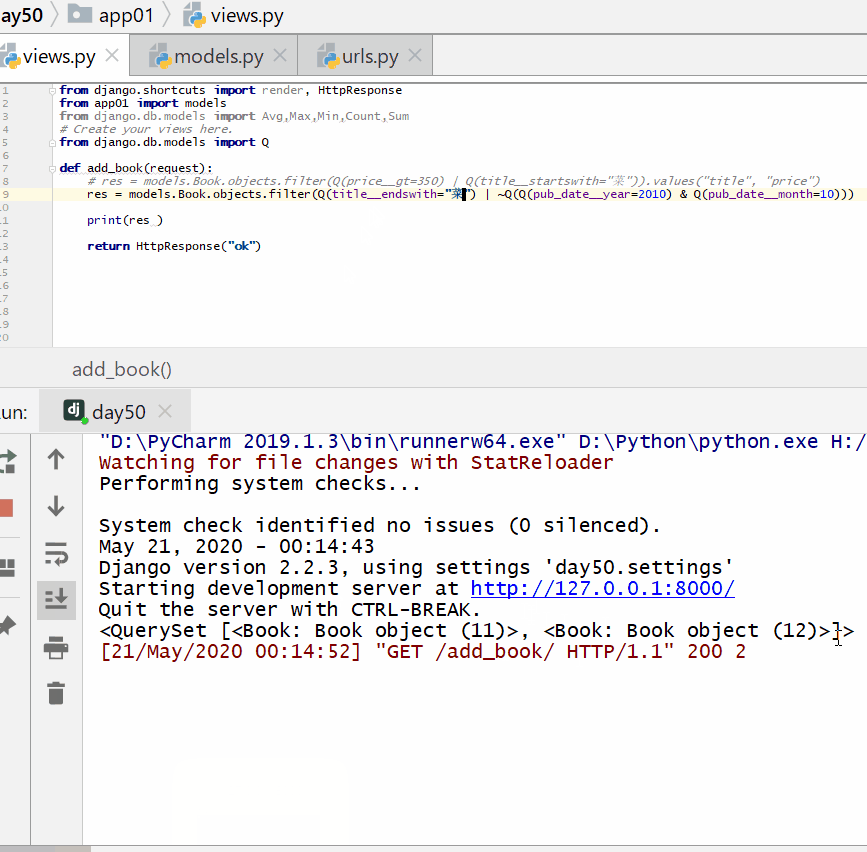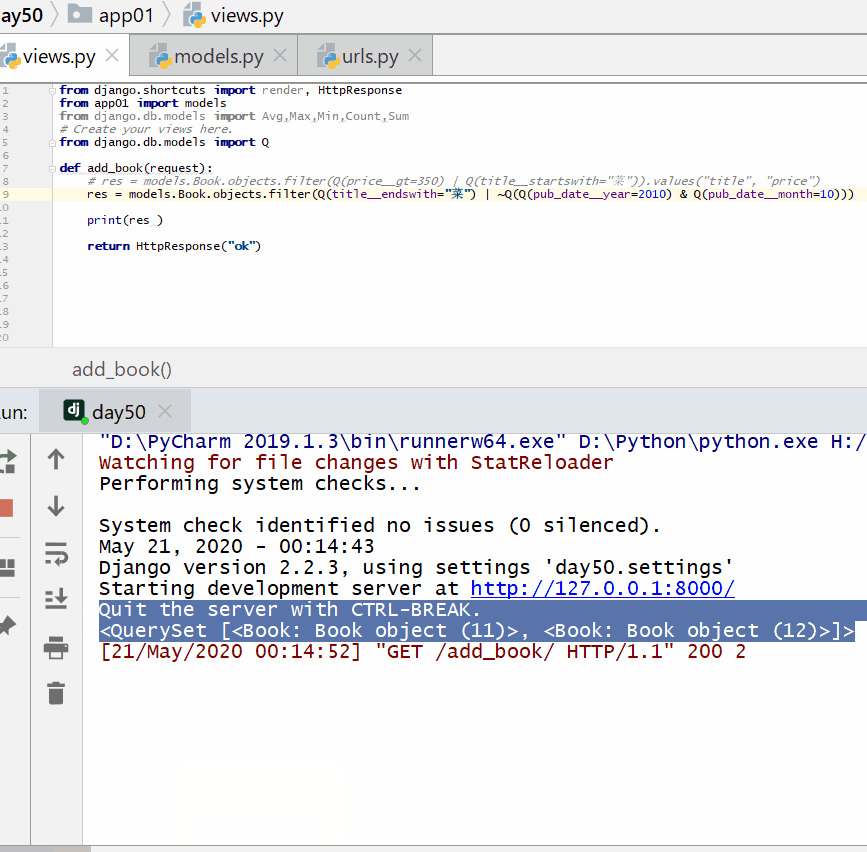
查询以"菜"结尾或者不是 2010 年 10 月份的书籍:
实例
print ( res )
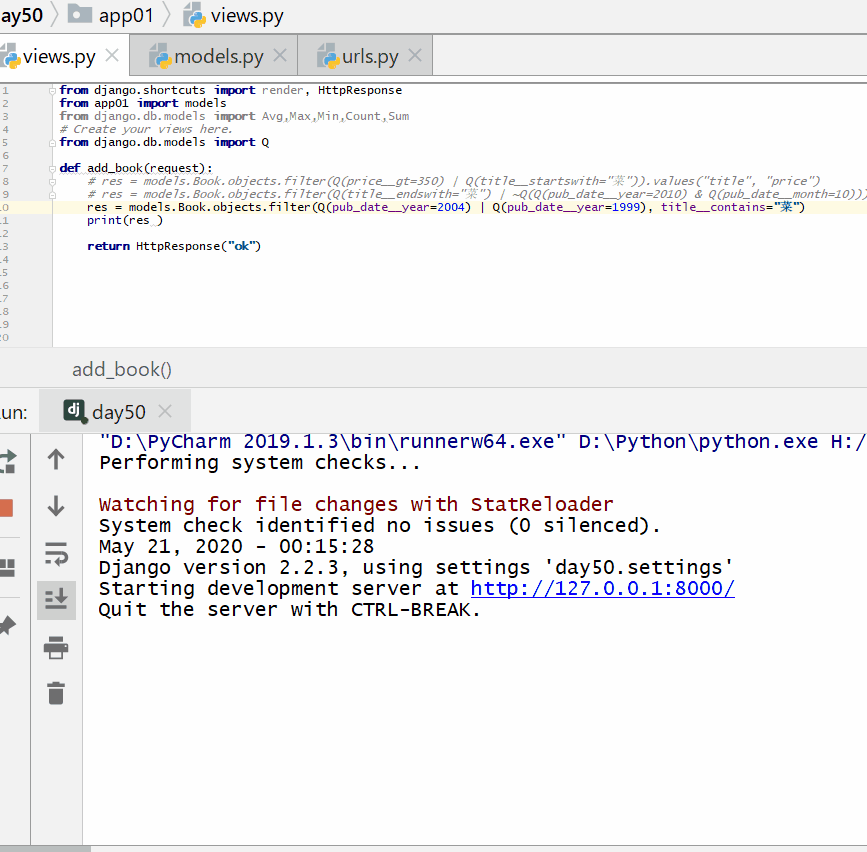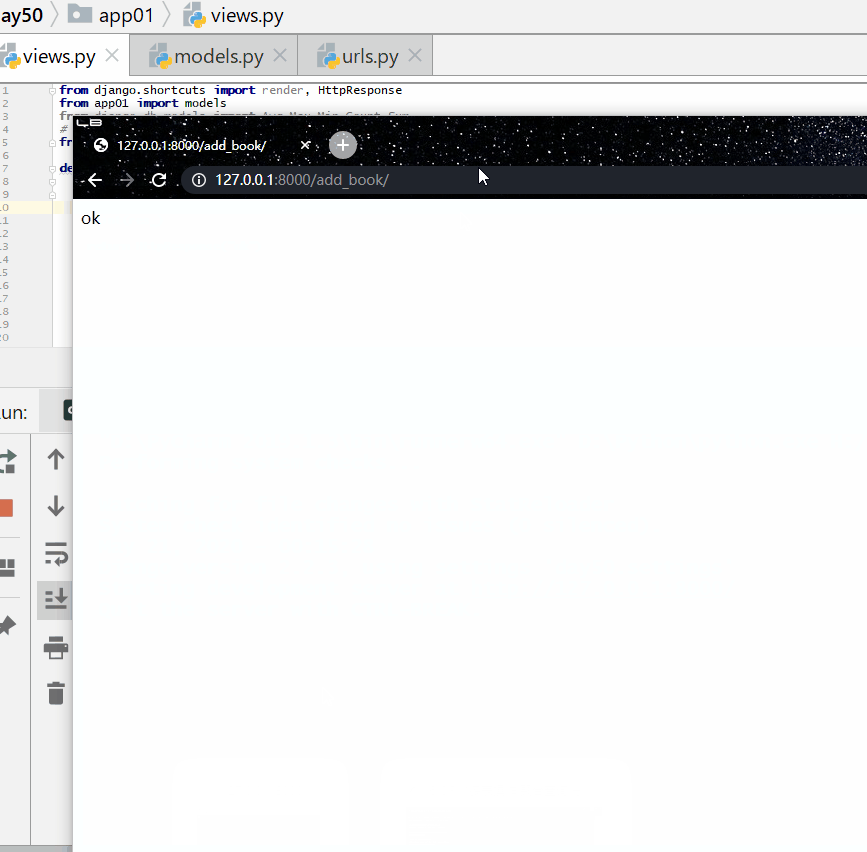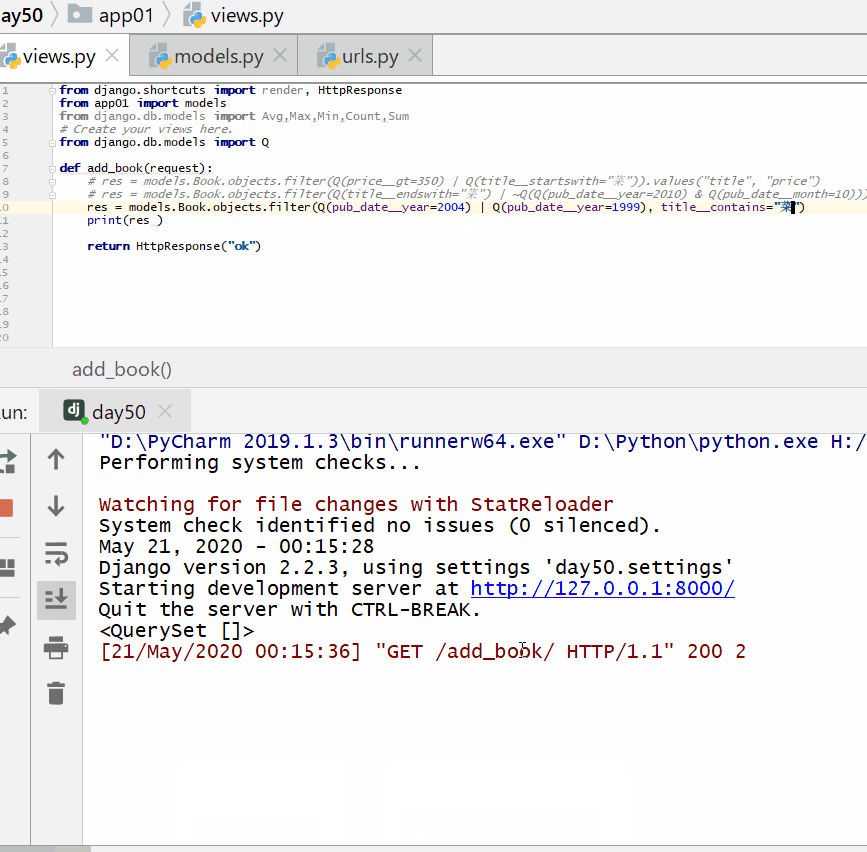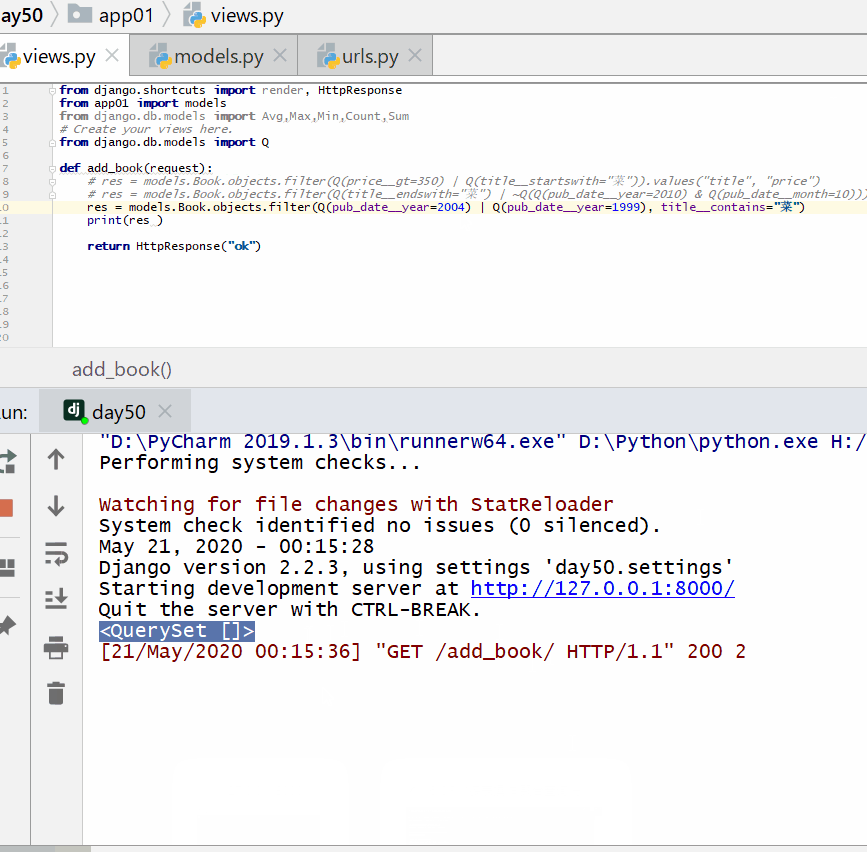
查询出版日期是 2004 或者 1999 年,并且书名中包含有"菜"的书籍。
Q 对象和关键字混合使用,Q 对象要在所有关键字的前面:
实例
print ( res )