Pandas 简介
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
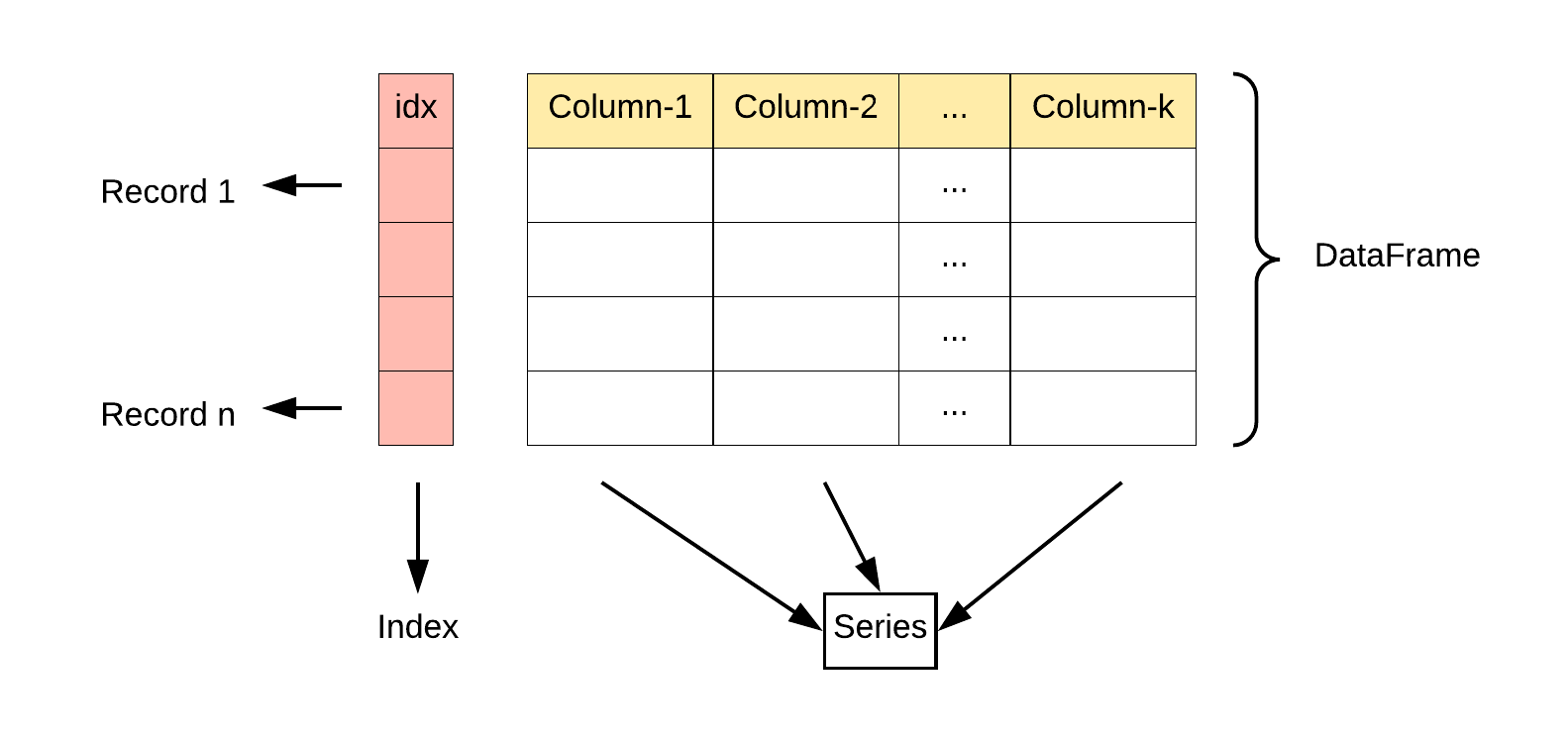
Pandas 主要引入了两种新的数据结构: DataFrame 和 Series 。
-
Series : 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。

-
DataFrame : 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。

DataFrame 可视为由多个 Series 组成的数据结构:
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
Pandas 应用
Pandas 在数据科学和数据分析领域中具有广泛的应用,其主要优势在于能够处理和分析结构化数据。
以下是 Pandas 的一些主要应用领域:
-
数据清洗和预处理: Pandas被广泛用于清理和预处理数据,包括处理缺失值、异常值、重复值等。它提供了各种方法来使数据更适合进行进一步的分析。
-
数据分析和统计: Pandas使数据分析变得更加简单,通过DataFrame和Series的灵活操作,用户可以轻松地进行统计分析、汇总、聚合等操作。从均值、中位数到标准差和相关性分析,Pandas都提供了丰富的功能。
-
数据可视化: 将Pandas与Matplotlib、Seaborn等数据可视化库结合使用,可以创建各种图表和图形,从而更直观地理解数据分布和趋势。这对于数据科学家、分析师和决策者来说都是关键的。
-
时间序列分析: Pandas在处理时间序列数据方面表现出色,支持对日期和时间进行高效操作。这对于金融领域、生产领域以及其他需要处理时间序列的行业尤为重要。
-
机器学习和数据建模: 在机器学习中,数据预处理是非常关键的一步,而Pandas提供了强大的功能来处理和准备数据。它可以帮助用户将数据整理成适用于机器学习算法的格式。
-
数据库操作: Pandas可以轻松地与数据库进行交互,从数据库中导入数据到DataFrame中,进行分析和处理,然后将结果导回数据库。这在数据库管理和分析中非常有用。
-
实时数据分析: 对于需要实时监控和分析数据的应用,Pandas的高效性能使其成为一个强大的工具。结合其他实时数据处理工具,可以构建实时分析系统。
Pandas 在许多领域中都是一种强大而灵活的工具,为数据科学家、分析师和工程师提供了处理和分析数据的便捷方式。
