Julia 字典和集合
前面几个章节我们学到了 Julia 数组 和 julia 元组 。
数组是一种集合,此外 Julia 也有其他类型的集合,比如字典和 set(无序集合列表)。
字典
字典是一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用 => 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
创建字典
创建字典的语法格式如下:
Dict("key1" => value1, "key2" => value2,,…, "keyn" => valuen)
以下实例创建一个简单的字典,键 A 对应的值为 1,键 B 对应的值为 2:
Dict("A"=>1, "B"=>2)
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia >
使用 for 来创建一个字典:
实例
Dict { String , Float64 } with 73 entries:
"285" = > - 0.965926
"310" = > - 0.766044
"245" = > - 0.906308
"320" = > - 0.642788
"350" = > - 0.173648
"20" = > 0.34202
"65" = > 0.906308
"325" = > - 0.573576
"155" = > 0.422618
"80" = > 0.984808
"335" = > - 0.422618
"125" = > 0.819152
"360" = > 0.0
"75" = > 0.965926
"110" = > 0.939693
"185" = > - 0.0871557
"70" = > 0.939693
"50" = > 0.766044
"190" = > - 0.173648
⋮ = > ⋮
键(Key)
字典中的键是唯一的, 如果我们为一个已经存在的键分配一个值,我们不会创建一个新的,而是修改现有的键。
查找 key
我们可以使用 haskey() 函数来检查字典是否包含指定的 key:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia > haskey ( first_dict, "A" )
false
julia > haskey ( D, "A" )
true
julia > haskey ( D, "Z" )
false
也可以使用 in() 函数来检查字典是否包含 键/值 对:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia > in ( ( "A" = > 1 ) , D )
true
julia > in ( ( "X" = > 220 ) , first_dict )
false
添加 key/value 对
我们可以在已存在的字典中添加一个新的 key/value 对,如下所示:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia > D [ "C" ] = 3
3
julia > D
Dict { String , Int64 } with 3 entries:
"B" = > 2
"A" = > 1
"C" = > 3
删除 key/value 对
我们可以使用 delete!() 函数删除已存在字典的 key:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
获取字典中所有的 key
我们可以使用 keys() 函数获取字典中所有的 key:
实例
KeySet for a Dict { String , Int64 } with 2 entries. Keys :
"B"
"A"
julia >
值(Value)
字典中的每个键都有一个对应的值。
查看字典所有值
我们可以使用 values() 查看字典所有值:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia > values ( D )
ValueIterator for a Dict { String , Int64 } with 2 entries. Values :
2
1
julia >
字典作为可迭代对象
我们可以将字典作为可迭代对象来查看键/值对:
实例
Dict { String , Int64 } with 2 entries:
"B" = > 2
"A" = > 1
julia > for kv in D
println ( kv )
end
"B" = > 2
"A" = > 1
实例中 kv 是一个包含每个键/值对的元组。
字典排序
字典是无序的,但我们可以使用 sort() 函数来对字典进行排序:
实例
Dict { String , Int64 } with 6 entries:
"S" = > 220
"U" = > 400
"T" = > 350
"W" = > 670
"V" = > 575
"R" = > 100
julia > for key in sort ( collect ( keys ( yssmx_dict ) ) )
println ( "$key => $(yssmx_dict[key])" )
end
R = > 100
S = > 220
T = > 350
U = > 400
V = > 575
W = > 670
我们可以使用 DataStructures.ji 包中的 SortedDict 数据类型让字典始终保持排序状态。
使用 DataStructures 包需要先安装它,可以在 REPL 的 Pkg 模式中,使用 add 命令添加 SortedDict。
在 REPL 中输入符号 ] ,进入 pkg 模式。
进入 pkg 模式
添加包预防语法格式:
add 包名
以下我们添加 DataStructures 包后,后面的实例就可以正常运行了:
(@v1.7) pkg> add DataStructures未注册的包,可以直接指定 url:
add https://github.com/fredrikekre/ImportMacros.jl
本地包:
add 本地路径/包名.jl
实例
julia > yssmx_dict = DataStructures. SortedDict ( "S" = > 220 , "T" = > 350 , "U" = > 400 , "V" = > 575 , "W" = > 670 )
DataStructures. SortedDict { String , Int64 , Base. Order . ForwardOrdering } with 5 entries:
"S" = > 220
"T" = > 350
"U" = > 400
"V" = > 575
"W" = > 670
julia > yssmx_dict [ "R" ] = 100
100
julia > yssmx_dict
DataStructures. SortedDict { String , Int64 , Base. Order . ForwardOrdering } with 6 entries:
"R" = > 100
"S" = > 220
"T" = > 350
"U" = > 400
"V" = > 575
"W" = > 670
Set(集合)
Julia Set(集合)是没有重复的对象数据集,所有的元素都是唯一的。以下是 set 和其他类型的集合之间的区别:
- set 中的元素是唯一的
- set 中元素的顺序不重要
set 用于创建不重复列表。
创建 Set 集合
借助 Set 构造函数,我们可以创建如下集合:
实例
Set { Any } ( )
julia > num_primes = Set { Int64 } ( )
Set { Int64 } ( )
julia > var_site = Set { String } ( [ "Google" , "yssmx" , "Taobao" ] )
Set { String } with 3 elements:
"Google"
"Taobao"
"yssmx"
我们可以使用 push!() 函数添加集合元素,如下所示:
实例
Set { String } with 4 elements:
"Google"
"Wiki"
"Taobao"
"yssmx"
我们可以使用 in() 函数查看元素是否存在于集合中:
实例
true
julia > in ( "Zhihu" , var_site )
false
常用操作
并集、交集和差集是我们可以对集合常用的一些操作, 这些操作对应的函数是 union()、intersect() 和 setdiff() 。
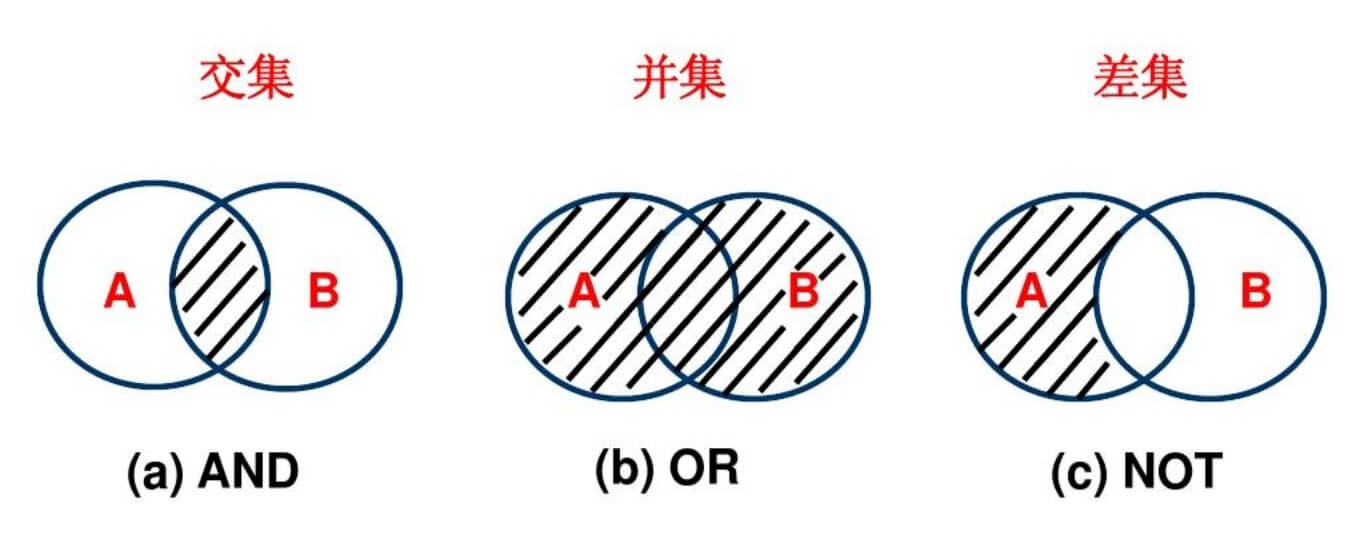
并集
两个集合 A,B,把他们所有的元素合并在一起组成的集合,叫做集合 A 与集合 B 的并集。实例
Set { String } with 4 elements:
"blue"
"green"
"black"
"red"
julia > B = Set ( [ "red" , "orange" , "yellow" , "green" , "blue" , "indigo" , "violet" ] )
Set { String } with 7 elements:
"indigo"
"yellow"
"orange"
"blue"
"violet"
"green"
"red"
julia > union ( A, B )
Set { String } with 8 elements:
"indigo"
"green"
"black"
"yellow"
"orange"
"blue"
"violet"
"red"
交集
集合 A 和 B 的交集是含有所有既属 A 又属于 B 的元素,而没有其他元素的集合。
实例
Set { String } with 3 elements:
"blue"
"green"
"red"
差集
集合 A 和 B 的差集是含有所有属 A 但不属于 B 的元素,即去除 B 与 A 重叠的元素。
实例
Set { String } with 1 element:
"black"
字典与集合常用函数实例
在下面的实例中,演示了字典中常用的函数,在集合中也同样适用:
创建两个字典 dict1 和 dict2:
实例
Dict { Int64 , String } with 2 entries:
100 = > "X"
220 = > "Y"
julia > dict2 = Dict ( 220 = > "Y" , 300 = > "Z" , 450 = > "W" )
Dict { Int64 , String } with 3 entries:
450 = > "W"
220 = > "Y"
300 = > "Z"
字典并集:
实例
4 -element Array { Pair { Int64 , String } , 1 } :
100 = > "X"
220 = > "Y"
450 = > "W"
300 = > "Z"
Intersect
julia > intersect ( dict1, dict2 )
1 -element Array { Pair { Int64 , String } , 1 } :
220 = > "Y"
字典差集:
实例
1 -element Array { Pair { Int64 , String } , 1 } :
100 = > "X"
合并字典:
实例
Dict { Int64 , String } with 4 entries:
100 = > "X"
450 = > "W"
220 = > "Y"
300 = > "Z"
查看字典中的最小值:
实例
Dict { Int64 , String } with 2 entries:
100 = > "X"
220 = > "Y"
julia > findmin ( dict1 )
( "X" , 100 )
